
Derivation of $\frac{dL}{dz}$
The derivation for $\frac{dL}{dz} = a - y$ from DeepLearning.AI.
By the chain rule: $\frac{dL}{dz} = \frac{dL}{da} \times \frac{da}{dz}$
We’ll do the following:
Step 1: $\frac{dL}{da}$
$L = -(y \times log(a) + (1-y) \times log(1-a))$
$\frac{dL}{da} = -y\times \frac{1}{a} - (1-y) \times \frac{1}{1-a}\times -1$
Note that the notational conventions are different in the ML world than the math world: here log always means the natural log.
$\frac{dL}{da} = \frac{-y}{a} + \frac{1-y}{1-a}= \frac{-y + ay + a - ay}{a(1-a)}$
So now we have:
$\frac{dL}{da} = \frac{a - y}{a(1-a)}$
Step 2: $\frac{da}{dz}$
$\frac{da}{dz} = \frac{d}{dz} \sigma(z)$
The derivative of a sigmoid has the form:
$\frac{d}{dz}\sigma(z) = \sigma(z) \times (1 - \sigma(z))$
Recall that $\sigma(z) = a$, because we defined “$a$”, the activation, as the output of the sigmoid activation function.
So we can substitute into the formula to get:
$\frac{da}{dz} = a (1 - a)$
Step 3: $\frac{dL}{dz}$
$\frac{dL}{dz} = \frac{a - y}{a(1-a)} \times a (1 - a)$
$\frac{dL}{dz} = a - y$
Shallow neural network


* and the last option
Computing a Neural Network’s Output
(Credit to Mahmoud Badry @2017)
Equations of Hidden layers:
 )
)
Here are some informations about the last image:
noOfHiddenNeurons = 4Nx = 3- Shapes of the variables:
W1is the matrix of the first hidden layer, it has a shape of(noOfHiddenNeurons,nx)b1is the matrix of the first hidden layer, it has a shape of(noOfHiddenNeurons,1)z1is the result of the equationz1 = W1*X + b, it has a shape of(noOfHiddenNeurons,1)a1is the result of the equationa1 = sigmoid(z1), it has a shape of(noOfHiddenNeurons,1)W2is the matrix of the second hidden layer, it has a shape of(1,noOfHiddenNeurons)b2is the matrix of the second hidden layer, it has a shape of(1,1)z2is the result of the equationz2 = W2*a1 + b, it has a shape of(1,1)a2is the result of the equationa2 = sigmoid(z2), it has a shape of(1,1)
Activation functions
(Credit to Mahmoud Badry @2017)
So far we are using sigmoid, but in some cases other functions can be a lot better.
Sigmoid can lead us to gradient decent problem where the updates are so low.
Sigmoid activation function range is [0,1]
A = 1 / (1 + np.exp(-z)) # Where z is the input matrixTanh activation function range is [-1,1] (Shifted version of sigmoid function)
In NumPy we can implement Tanh using one of these methods:
A = (np.exp(z) - np.exp(-z)) / (np.exp(z) + np.exp(-z)) # Where z is the input matrixOr
A = np.tanh(z) # Where z is the input matrix
It turns out that the tanh activation usually works better than sigmoid activation function for hidden units because the mean of its output is closer to zero, and so it centers the data better for the next layer.
Sigmoid or Tanh function disadvantage is that if the input is too small or too high, the slope will be near zero which will cause us the gradient decent problem.
One of the popular activation functions that solved the slow gradient decent is the RELU function.
RELU = max(0,z) # so if z is negative the slope is 0 and if z is positive the slope remains linear.So here is some basic rule for choosing activation functions, if your classification is between 0 and 1, use the output activation as sigmoid and the others as RELU.
Leaky RELU activation function different of RELU is that if the input is negative the slope will be so small. It works as RELU but most people uses RELU.
Leaky_RELU = max(0.01z,z) #the 0.01 can be a parameter for your algorithm.In NN you will decide a lot of choices like:
- No of hidden layers.
- No of neurons in each hidden layer.
- Learning rate. (The most important parameter)
- Activation functions.
- And others..
It turns out there are no guide lines for that. You should try all activation functions for example.
Why do you need non-linear activation functions?
- If we removed the activation function from our algorithm that can be called linear activation function.
- Linear activation function will output linear activations
- Whatever hidden layers you add, the activation will be always linear like logistic regression (So its useless in a lot of complex problems)
- You might use linear activation function in one place - in the output layer if the output is real numbers (regression problem). But even in this case if the output value is non-negative you could use RELU instead.
Derivatives of activation functions
Derivation of Sigmoid activation function:
1 2 3g(z) = 1 / (1 + np.exp(-z)) g'(z) = (1 / (1 + np.exp(-z))) * (1 - (1 / (1 + np.exp(-z)))) g'(z) = g(z) * (1 - g(z))Derivation of Tanh activation function:
1 2g(z) = (e^z - e^-z) / (e^z + e^-z) g'(z) = 1 - np.tanh(z)^2 = 1 - g(z)^2Derivation of RELU activation function:
1 2 3g(z) = np.maximum(0,z) g'(z) = { 0 if z < 0 1 if z >= 0 }Derivation of leaky RELU activation function:
1 2 3g(z) = np.maximum(0.01 * z, z) g'(z) = { 0.01 if z < 0 1 if z >= 0 }
Matrix Dimensions
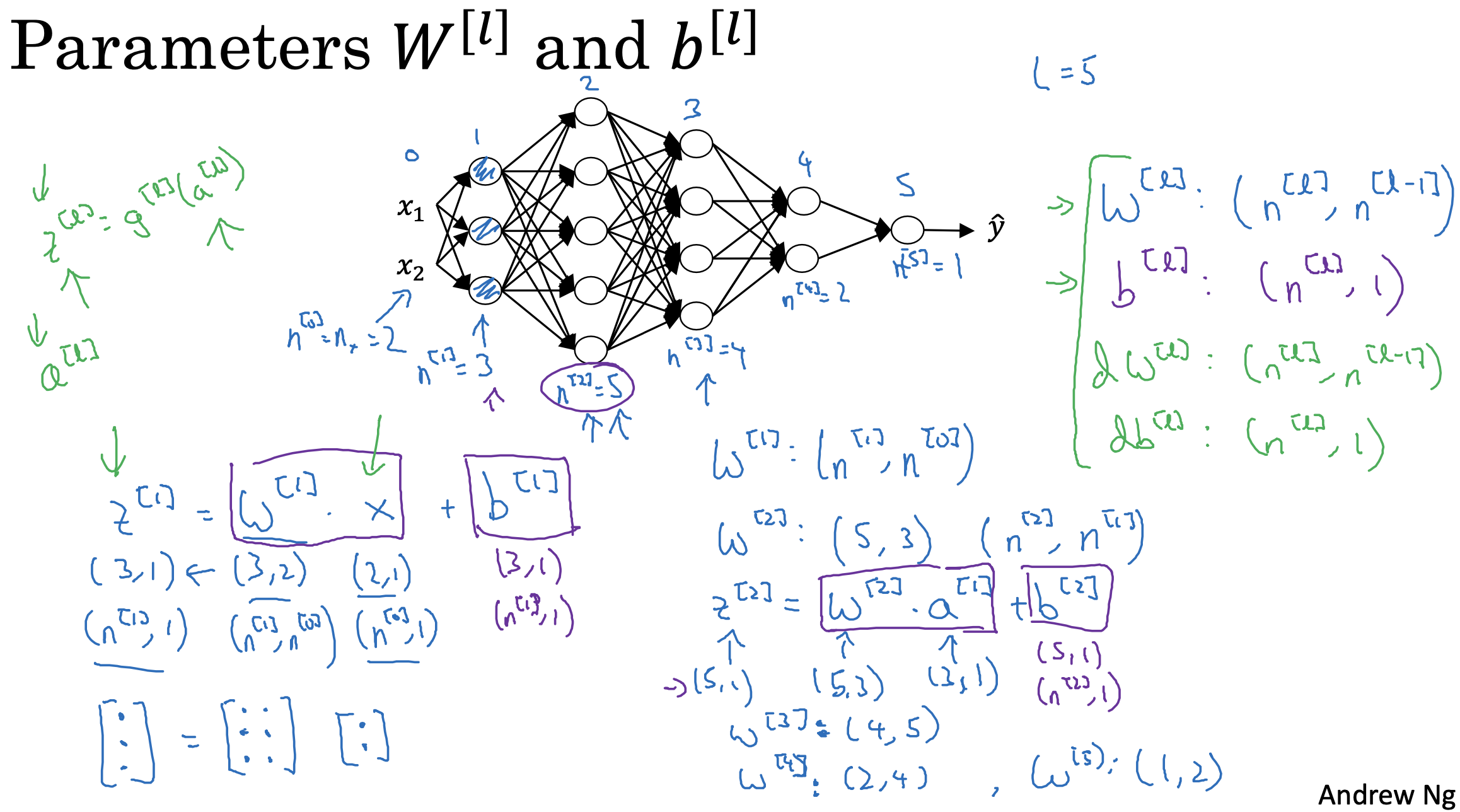
Practical aspects of Deep Learning
Regularization: increase bias, reduce variance
Structuring Machine Learning Projects
Stakeholders must define thresholds for satisficing metrics, leaving the optimizing metric unbounded.
CNN

