The weekly report is a summary of the work I have done in the past week. It is a good way to keep track of my progress and to keep myself accountable. I will write it every week (hopefully).
The feature image is the wave form of “Duke”.
Feb. 14, 2023
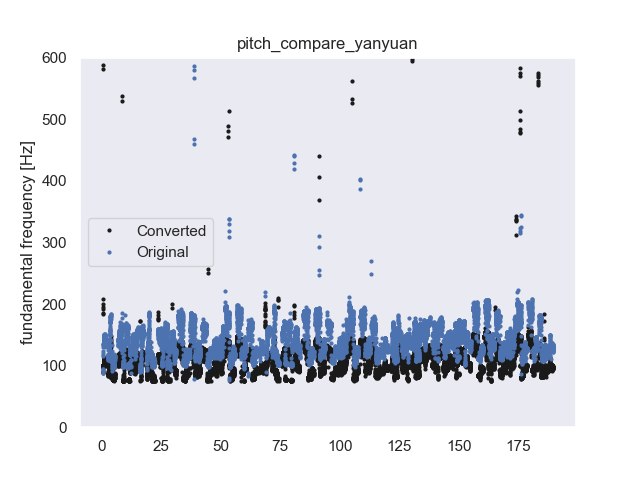
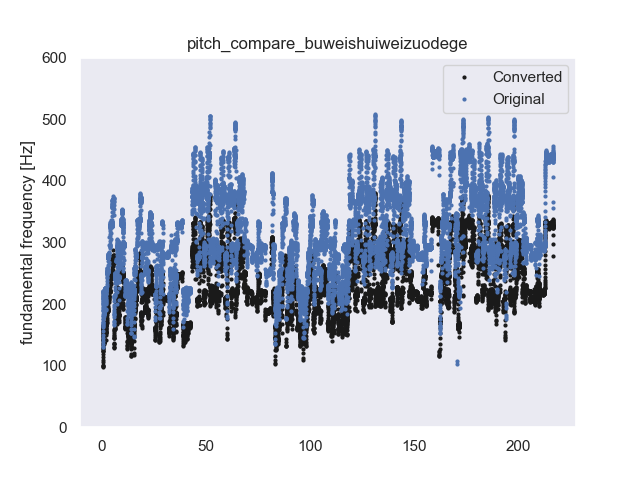
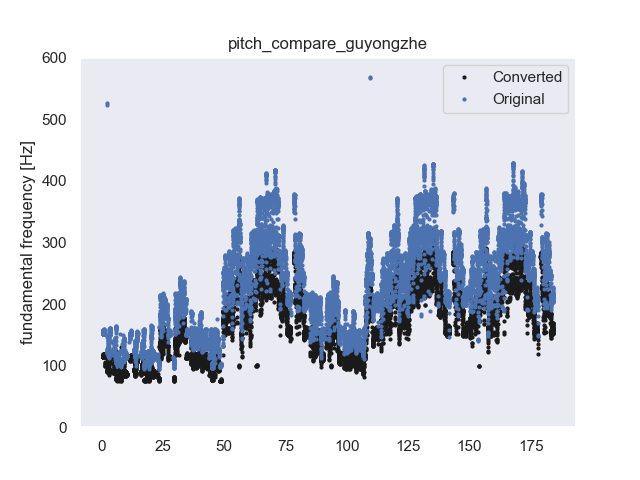
| Original | Converted1 | Observation | Converted2 |
|---|---|---|---|
| Breathing with electric sound | |||
| Breathing with electric sound (0:02); Yi (1:02); Zhan a (2:48) | |||
| Choose the most similar source | |||
| Almost every breathing with electric sound (1:22, 1:40) | |||
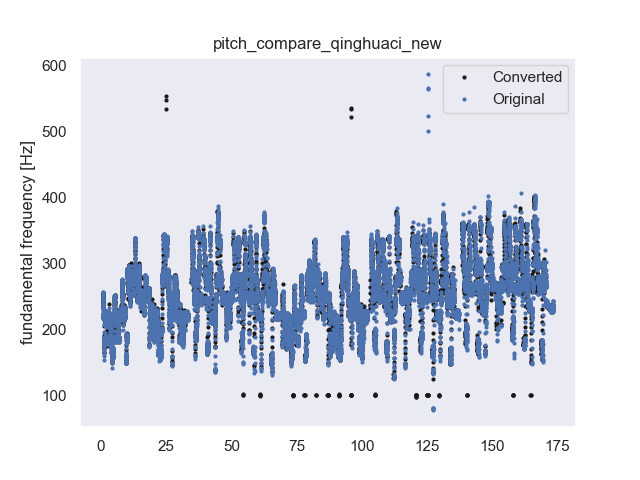
| Bad performance on low pitch | |||
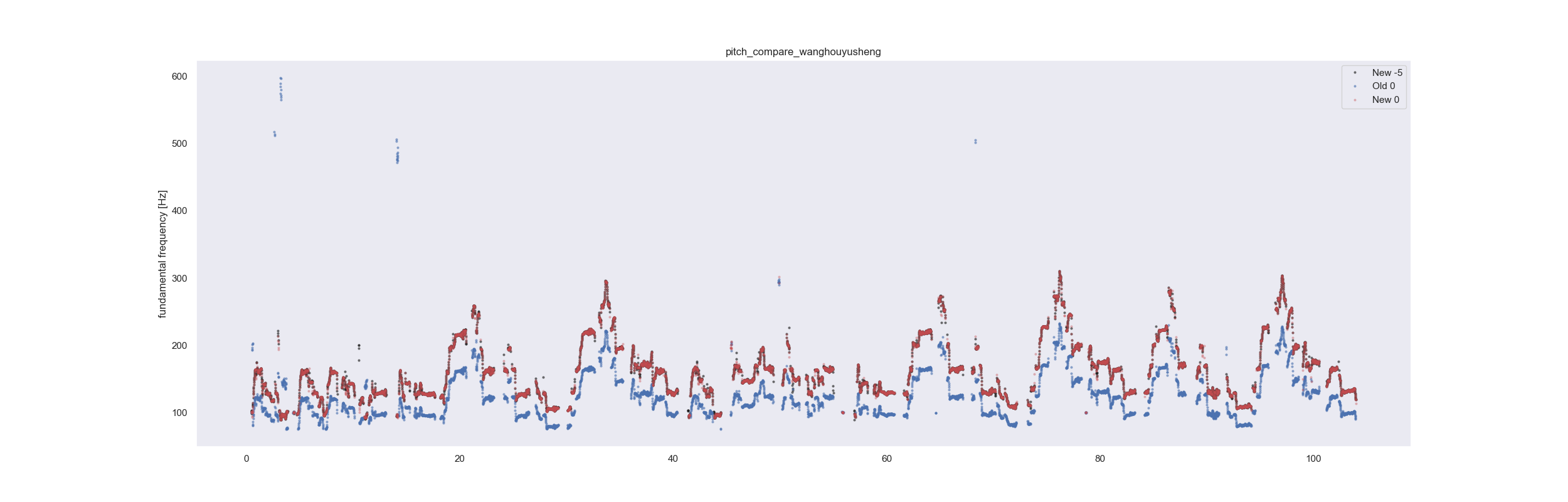
| Bad performance on low pitch | new model 0 pitch old model 0 pitchnew model -5 pitch | ||
| Breathing with electric sound; Ai (0:47) Wai (1:09) | |||
| Bad performance when two singers are involved at once (1:20, 3:20), high-pitch (1:02) | |||
| Legging (1:47), Bad performance in the second part (2:28) | |||
| Mixed with instrumental sound The other speaker with 38 pieces |
Previous Week
Feb. 7, 2023
Implementation of so-vits-svc. Models are trained on two speakers, one from a song in M4Singer dataset and the other from self-recorded 80 pieces of songs. The model is able to convert the voice from one singer to another. The first few songs are from untrained tenor speakers in the M4Singer dataset. The last two songs are web-downloaded songs. The vocal part is extracted by UVR5 using MDX-Net. The model is trained in 693 iterations with 9000 global steps.
| Original | Converted | Observation |
|---|---|---|
| Breathing with electric sound | ||
| Breathing with electric sound (0:02); Yi (1:02); Zhan a (2:48) | ||
| Choose the most similar source | ||
| Almost every breathing with electric sound (1:22, 1:40) | ||
| Bad performance on low pitch | ||
| Bad performance on low pitch | ||
| Breathing with electric sound; Ai (0:47) Wai (1:09) | ||
| Bad performance when two singers are involved at once (1:20, 3:20), high-pitch (1:02) | ||
| Legging (1:47), Bad performance in the second part (2:28) | ||
| Mixed with instrumental sound The other speaker with 38 pieces |
Dec. 16, 2022
A Universal Music Translation Network
The paper proposes a universal music translation network, which can translate music from one style to another.
Input-WaveNet Encoder-Domain Confusion Network-Output-Multiple WaveNet Decoders
Domain confusion network is a network that can learn the mapping between the two domains (provides an adversarial signal to the encoder)
from Deep Domain Confusion: Maximizing for Domain Invariance
If we can learn a representation that minimizes the distance between the source and target distributions, then we can train a classifier on the source labeled data and directly apply it to the target domain with minimal loss in accuracy. To minimize this distance, we consider the standard distribution distance metric, Maximum Mean Discrepancy (MMD). This distance is computed with respect to a particular representation, $\psi(·)$. In our case, we define a representation, $\psi(·)$, which operates on source data points, $x_{s} \in X_{S}$, and target data points, $x_{t} \in X_{T}$ . Then an empirical approximation to this distance is computed as followed: $$\begin{array}{l} \operatorname{MMD}\left(X_{S}, X_{T}\right)= \ \left|\frac{1}{\left|X_{S}\right|} \sum_{x_{s} \in X_{S}} \phi\left(x_{s}\right)-\frac{1}{\left|X_{T}\right|} \sum_{x_{t} \in X_{T}} \phi\left(x_{t}\right)\right| \end{array}$$
To minimze the distance between domains (or maximize the domain confusion) and get a representation which is conducive to training strong classifiers, we try to minimize the loss: $$\mathcal{L}=\mathcal{L}_{C}(X_{L}, y)+\lambda \operatorname{MMD}^{2}(X_{S}, X_{T})$$ where $\mathcal{L}_{C}(X_{L}, y)$ denotes classification loss on the available labeled data, $X_{L}$, and the ground truth labels, $y$, and $\operatorname{MMD}(X_{S}, X_{T})$ denotes the distance between the source data, $X_{S}$ and the target data, $X_{T}$. The hyperparameter $\lambda$ determines how strongly we would like to confuse the domains.
Unsupervised Singing Voice Conversion
The paper proposes a method to convert singing voice from one singer to another.
The method is based on the idea of cycle-consistency.
Similar architecture as the above paper.
Mixup training: functions trains on an additional set of virtual samples created by combining two samples and using the same random weight that is sampled from the Beta distribution $x^{\prime}=\beta x_{1}+(1-\beta) x_{2}$ and $y^{\prime}=\beta y_{1}+(1-\beta) y_{2}$. A $\beta$ is often close close to zero or to one.
Two training phases:
Only the reconstruction loss and the and the domain confusion loss. Samples are being reconstructed using the autoencoding path of the same singer $j$.
Synthetic samples are being generated by converting from a sample of singer $j$ to a mixup voice that combines the vocal characteristics of two singers $j$ and $j^{\prime}$. These samples are used as training samples for a backtranslation procedure, in which they are translated back to singer $j$ and a loss then compares to the original sample of singer $j$.
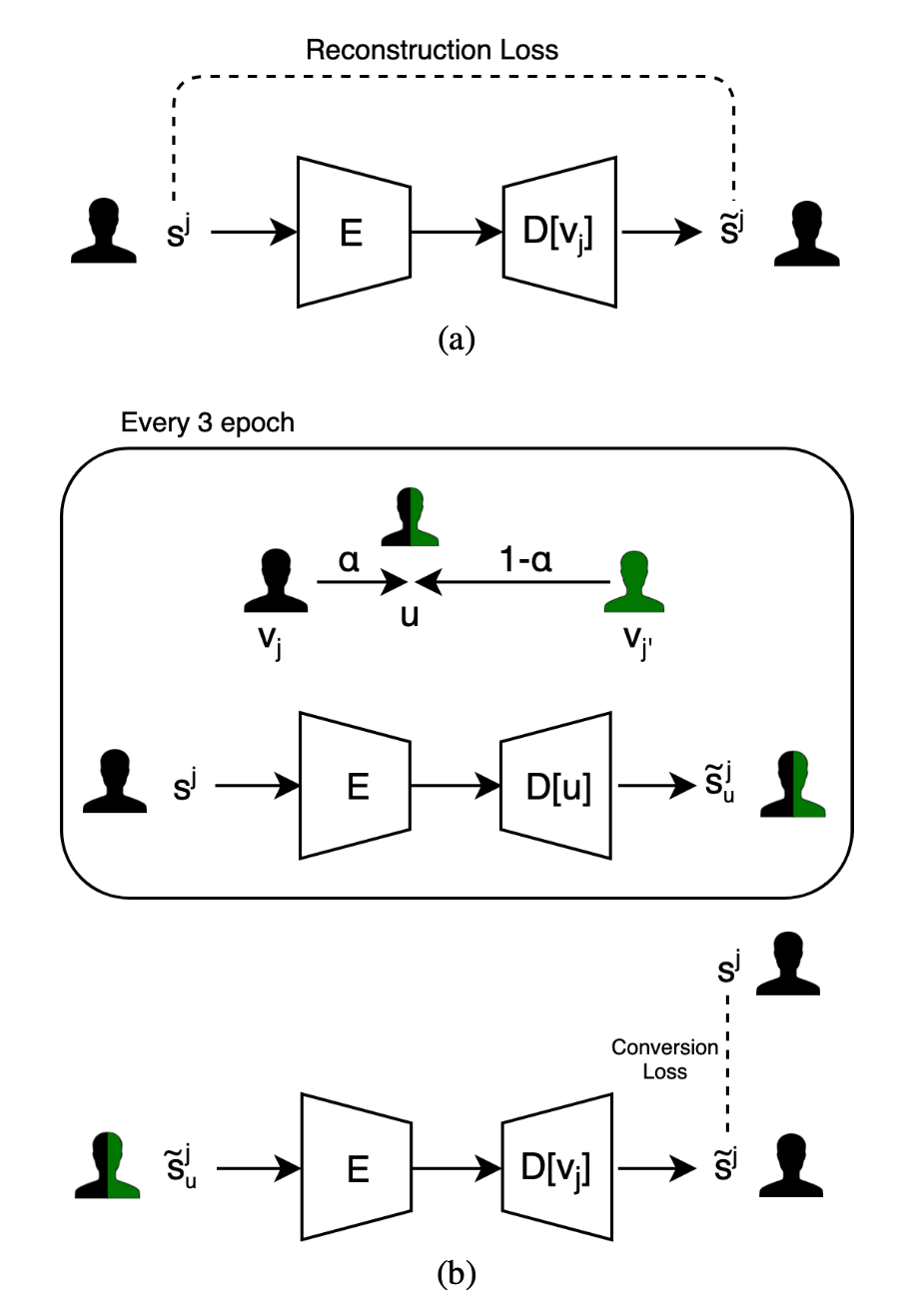
“Teacher forcing” is a technique in which the target word is passed as the next input to the decoder (uses ground truth as input, instead of model output from a prior time step as an input).
Nov. 18, 2022
Watch the 深蓝学院 recording regarding TTS.
- The topics include seq2seq, attention, and vocoder.
- Below are some important slides.



Train the Fastspeech2
The training results are shown below

As we can see, the validation loss is not decreasing, so I just stop the training. (37000 steps)
Demo audios



Comparision with the result we got from Tacotron2 (188000 steps)