TTS Tutorial
icassp2022/README.md at main · tts-tutorial/icassp2022 · GitHub
Tacotron & Tacotron2
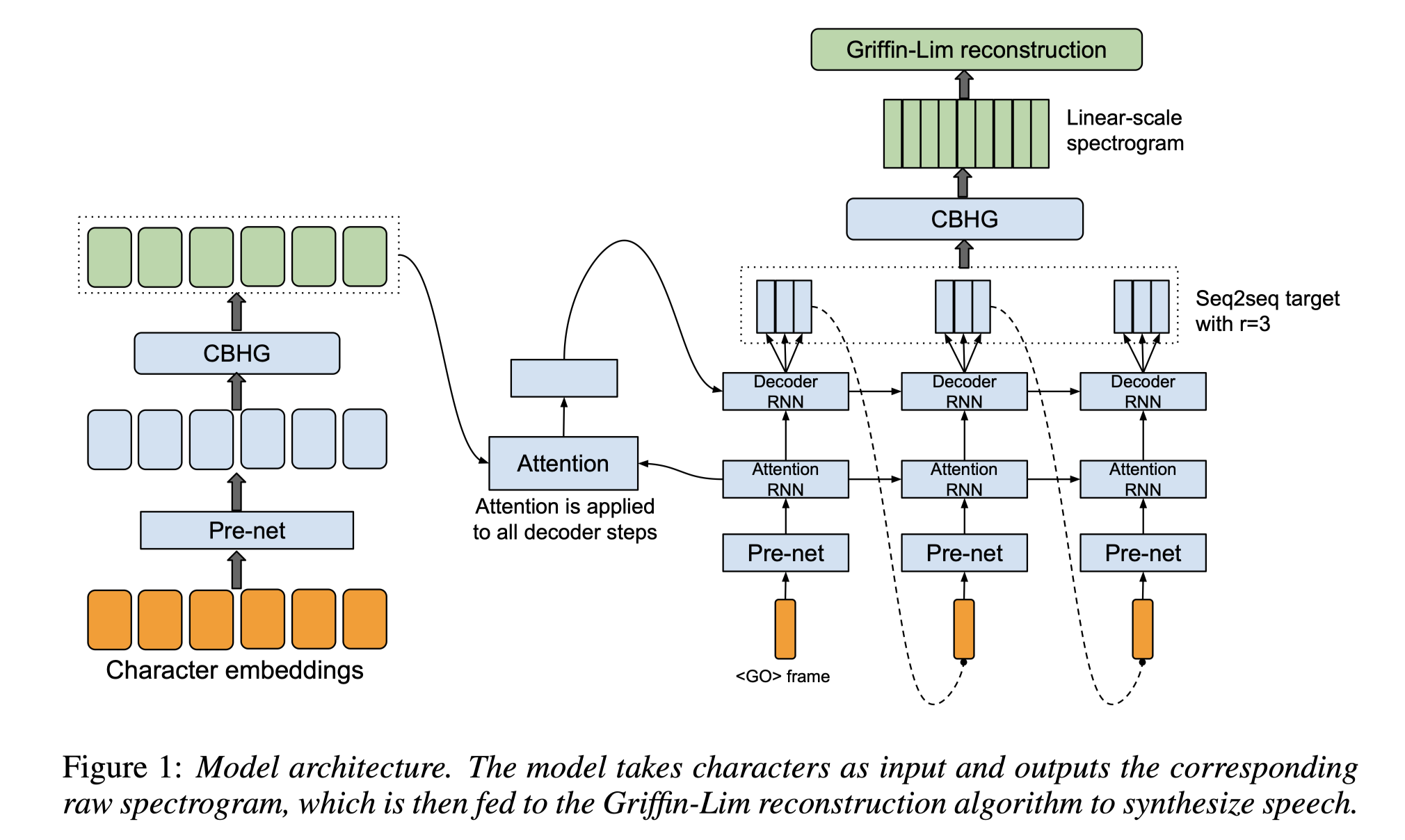
Feature
Take characters as input and output mel-spectrogram.
Use attention mechanism to align the input and output.
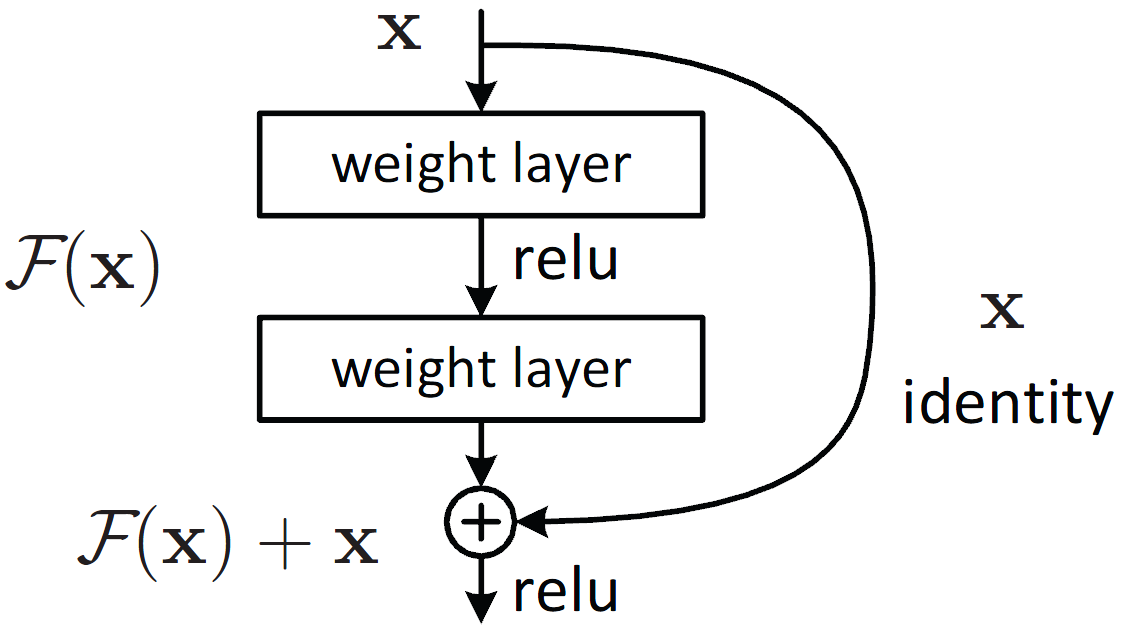
A Highway Network is an architecture designed to ease gradient-based training of very deep networks.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17def forward(self, x): """ :param x: tensor with shape of [batch_size, size] :return: tensor with shape of [batch_size, size] applies σ(x) ⨀ (f(G(x))) + (1 - σ(x)) ⨀ (Q(x)) transformation | G and Q is affine transformation, f is non-linear transformation, σ(x) is affine transformation with sigmoid non-linearition and ⨀ is element-wise multiplication """ for layer in range(self.num_layers): gate = F.sigmoid(self.gate[layer](x)) nonlinear = self.f(self.nonlinear[layer](x)) linear = self.linear[layer](x) x = gate * nonlinear + (1 - gate) * linear return xA Residual Network is a neural network that is trained with the residual learning framework. The basic building block of a residual network is the residual block, which takes an input and produces an output with the same dimensionality. The output of the residual block is calculated as:
$$y = f(x) + x$$where $f(x)$ is a function that maps $x$ to a different output, and $x$ is the input to the residual block. The function $f(x)$ is often a deep neural network. The main idea of residual learning is to train such a residual network, where the function $f(x)$ is learned in an end-to-end fashion and can be arbitrarily deep when computing the mapping $f(x)$. The residual block allows the network to learn an effective transformation from the input to the output, and also allows it to learn an identity mapping with very little additional effort. The identity mapping is useful because it allows the network to skip layers when the input is close to the output, which can be beneficial when the network is very deep.
Gated Recurrent Unit (GRU) is a type of recurrent network. It only has two gates, reset gate and update gate. The reset gate controls how much past information to forget, and the update gate controls how much past information to keep. The GRU is a simplified version of the LSTM, and it has fewer parameters than the LSTM. The GRU is also faster to compute than the LSTM.
PreNet is a network that is used before the RNN layers in the Tacotron model. It is a two-layer feed-forward network with ReLU activation. The first layer has 256 units, and the second layer has 128 units. The output of the PreNet is used as the input to the RNN layers.
1 2 3 4 5 6 7 8 9 10 11 12 13 14class PreNet(nn.Module): def __init__(self, in_dim, sizes=[256, 128]): super(PreNet, self).__init__() self.layers = nn.ModuleList() for size in sizes: linear = nn.Linear(in_dim, size) self.layers.append(linear) in_dim = size def forward(self, x): for linear in self.layers: x = F.relu(linear(x)) x = F.dropout(x, p=0.5, training=self.training) return xThe decoder is a bidirectional GRU with 1024 units. The decoder takes the output of the attention mechanism as input. The output of the decoder is used to predict the mel-spectrogram.
<GO> frame is a vector of zeros. It is used as the first input to the decoder. The
frame is used to predict the first mel-spectrogram frame. Output layer reduction factor is the number of frames that the output layer predicts for each input frame. The output layer reduction factor is 2 for the Tacotron model.
Reduction in output timesteps: Since we produce several similar looking speech frames, the attention mechanism won’t really move from frame to frame. To alleviate this problem, the decoder is made to swallow inputs only every ‘r’ frames, while we dump r frames as output. For example, if r=2, then we dump 2 frames as output, but we only feed in the last frame as input to the decoder. Since we reduce the number of timesteps, the recurrent model should have an easier time with this approach. The authors note that this also helps the model in learning attention. (Copied from here)
For example, a Seq2seq target with r=2 in the decoder in Tacotron can be represented as:
1 2 3 4# target: [batch_size, seq_len] # r: reduction factor # output: [batch_size, seq_len // r, r] output = target[:, :target.size(1) // r * r].view(-1, r)In Tacotron 2, the output layer reduction factor is 1. The output layer predicts the mel-spectrogram frame for each input frame.
Other differences in Tacotron 2:
- The decoder is a unidirectional GRU with 1024 units.
- The decoder takes the output of the attention mechanism and the previous mel-spectrogram frame as input.
- The decoder predicts the stop token.
- The stop token is used to determine when to stop generating mel-spectrogram frames.
The attention mechanism is a location-sensitive attention mechanism. It uses the decoder’s hidden state and the encoder’s outputs to calculate the attention weights. The attention weights are then used to calculate the context vector, which is used to predict the mel-spectrogram.
- Attention alignment is the alignment between the input and output. The attention alignment is used to calculate the attention weights.
Feed-forward network is a network with one or more hidden layers between the input and output layers. The hidden layers are fully connected layers. The output layer is a two-layer feed-forward network with ReLU activation. The first layer has 1024 units, and the second layer has 80 units.
The stop token is a binary value that indicates whether the synthesis is finished. The stop token is predicted by a single fully connected layer with a sigmoid activation function. The stop token is used to determine when to stop the synthesis.
FastSpeech
Sequence to sequence learning is usually built on the encoder-decoder framework. The encoder is a deep neural network that encodes the input sequence into a fixed-length vector. The decoder is a deep neural network that decodes the fixed-length vector into the output sequence.
Non-Autoregressive Sequence Generation is a sequence generation method that does not require the decoder to generate the output sequence in an autoregressive manner. The decoder can generate the output sequence in parallel.
Feed-forward Transformer is a sequence-to-sequence model that uses the encoder-decoder framework. The encoder is a multi-layer Transformer encoder. The decoder is a multi-layer Transformer decoder. The encoder and decoder are trained in an end-to-end fashion.
Self Attention Mask is a mask that is used to prevent the model from attending to the future tokens.
Positional Encoding is a technique that is used to add information about the relative or absolute position of the tokens in the sequence to the token embeddings. The positional encoding is added to the embeddings of the input tokens.
MelGAN
- Dilated Convolution: Dilated Convolutions are a type of convolution that “inflate” the kernel by inserting holes between the kernel elements. An additional parameter $l$ (dilation rate) indicates how much the kernel is widened. There are usually $l-1$ spaces inserted between kernel elements.