Modified on Eric’s code and README.
Labelling
Download Coalabeler via http://www.colabeler.com and install it
Open Colabeler and create a new project
Choose the Image Folder Classification Values: particle

Open the project you created, note that it may not work at once, try a few times until images show up
In your keyboard, type “R” to select the Rectangle tool, and start labelling. Remember to type your label name for the first time

During your labelling, please remember to click “✅” or Crtl+s to save your work. This software is not stable
After you finishing one image’s labelling, use you direction key to go to the next image.
After all the labelling, select Export and choose XML export method. (You can first try to export once you start labelling, this is also not stable on MacOS so you may try many times, or try restarting your computer)
Installation
Conda
1
2
3
| # Tensorflow GPU
conda env create -f conda-gpu.yml
conda activate yolov3-tf2-gpu
|
Cutting images
File: Cutting.ipynb
Usage: To cut images into smaller pieces. You can find the detailed steps in the file.
Training
Files
| Name | Description |
|---|
| benchmark/ | Temporary directory for mAP calculation. |
| benchmark.py | Calculate mAP for files in benchmark/ . |
| checkpoints/ | Store the training models in each epoch. |
| conda-cpu.yml | Conda environment file for cpu. |
| conda-gpu.yml | Conda environment file for gpu. |
| convert.py | Convert YoloV3 weights into tensor-flow model. |
| data/ | Temporary dictionary for data storage. |
| data_convert.py | Convert labeled figure into tfrecords. |
| detect_list.py | Detect a list of image in tfrecords. |
| detect.py | Detect a single image. |
| logs/ | Store tenser-board files in training. |
| model_mAP.py | Calculate mAP for models in each epoch. |
| samples/ | Store image samples. |
| train.py | Program for traning the model. |
| yolov3_tf2/ | Files for YoloV3 model. |
| detect1.py | My modified version of detect.py |
Convert pre-trained Darknet weights (for COCO dataset)
1
2
| wget https://pjreddie.com/media/files/yolov3.weights -O data/yolov3.weights
python convert.py --weights ./data/yolov3.weights --output ./checkpoints/yolov3.tf
|
Prepare Training Dataset
In our dataset, the labeled dataset is stored in label.txt, in which the labels are arranged as follows:
1
2
3
4
| Path_1 Xmin_1,Ymin_1,Xmax_1,Ymax_1 ... Xmin_n1,Ymin_n1,Xmax_n1,Ymax_n1
Path_2 Xmin_1,Ymin_1,Xmax_1,Ymax_1 ... Xmin_n2,Ymin_n2,Xmax_n2,Ymax_n2
...
Path_m Xmin_1,Ymin_1,Xmax_1,Ymax_1 ... Xmin_nm,Ymin_nm,Xmax_nm,Ymax_nm
|
You may use data_convert.py to convert the images into tfrecords for training.
Example:
1
| python data_convert.py --dataset ./label.txt
|
Training model
The train.py takes some command line arguments and trains the model. Please see Command Line Args Reference for more information.
Example:
1
| python train.py --classes ./data/particle.names --dataset ./data/particle_train.tfrecord --val_dataset ./data/particle_val.tfrecord --epochs 25 --learning_rate 1e-4 --num_classes 1 --transfer darknet --weights ./checkpoints/yolov3.tf --weights_num_classes 80
|
Benchmark
The model for each epoch can be found in checkpoints/. You can use model_mAP.py to obtain the mAP of each model in both training set and validation set. (Make sure you use the same validation dataset as training.)
Command Line Args Reference
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
| convert.py:
--output: path to output
(default: './checkpoints/yolov3.tf')
--[no]tiny: yolov3 or yolov3-tiny
(default: 'false')
--weights: path to weights file
(default: './data/yolov3.weights')
--num_classes: number of classes in the model
(default: '80')
(an integer)
detect.py:
--classes: path to classes file
(default: './data/particle.names')
--image: path to input image
(default: './data/girl.png')
--num_classes: number of classes in the model
(default: '80')
(an integer)
--output: path to output image
(default: './output.jpg')
--size: resize images to
(default: '416')
(an integer)
--tfrecord: tfrecord instead of image
--weights: path to weights file
(default: './checkpoints/yolov3.tf')
train.py:
--batch_size: batch size
(default: '8')
(an integer)
--classes: path to classes file
(default: './data/particle.names')
--dataset: path to dataset
(default: '')
--epochs: number of epochs
(default: '2')
(an integer)
--learning_rate: learning rate
(default: '0.0001')
(a number)
--mode: <fit|eager_fit|eager_tf>: fit: model.fit, eager_fit:
model.fit(run_eagerly=True), eager_tf: custom GradientTape
(default: 'fit')
--num_classes: number of classes in the model
(default: '1')
(an integer)
--size: image size
(default: '416')
(an integer)
--transfer: <none|darknet|no_output|frozen|fine_tune>: none: Training from
scratch, darknet: Transfer darknet, no_output: Transfer all but output,
frozen: Transfer and freeze all, fine_tune: Transfer all and freeze darknet
only
(default: 'none')
--val_dataset: path to validation dataset
(default: '')
--weights: path to weights file
(default: './checkpoints/yolov3.tf')
--weights_num_classes: specify num class for `weights` file if different,
useful in transfer learning with different number of classes
(an integer)
data_convert.py:
--dataset: path to dataset label file
(default: '')
--output: path to output folder
(default: 'data/')
--subset: get a subset of training set (0 ~ 1)
(default: '1.0')
(a number)
--val_split: validation split
(default: '0.2')
(a number)
detect_list.py:
--batch_size: number of batch size for detection
(default: '12')
(an integer)
--classes: path to classes file
(default: './data/particle.names')
--num_classes: number of classes in the model
(default: '1')
(an integer)
--size: resize images to
(default: '416')
(an integer)
--tfrecord: path to tfrecord
--weights: path to weights file
(default: './checkpoints/yolov3.tf')
model_mAP.py:
--batch_size: batch size
(default: '8')
(an integer)
--classes: path to classes file
(default: './data/particle.names')
--epochs: ending epochs to calcuate mAP
(default: '1')
(an integer)
--epochs_start: starting epochs to calcuate mAP
(default: '1')
(an integer)
--num_classes: number of classes in the model
(default: '1')
(an integer)
--size: image size
(default: '416')
(an integer)
--train_dataset: path to dataset
(default: './data/particle_train.tfrecord')
--val_dataset: path to validation dataset
(default: './data/particle_val.tfrecord')
--weights_path: path to weights files
(default: './checkpoints/')
|
Detection
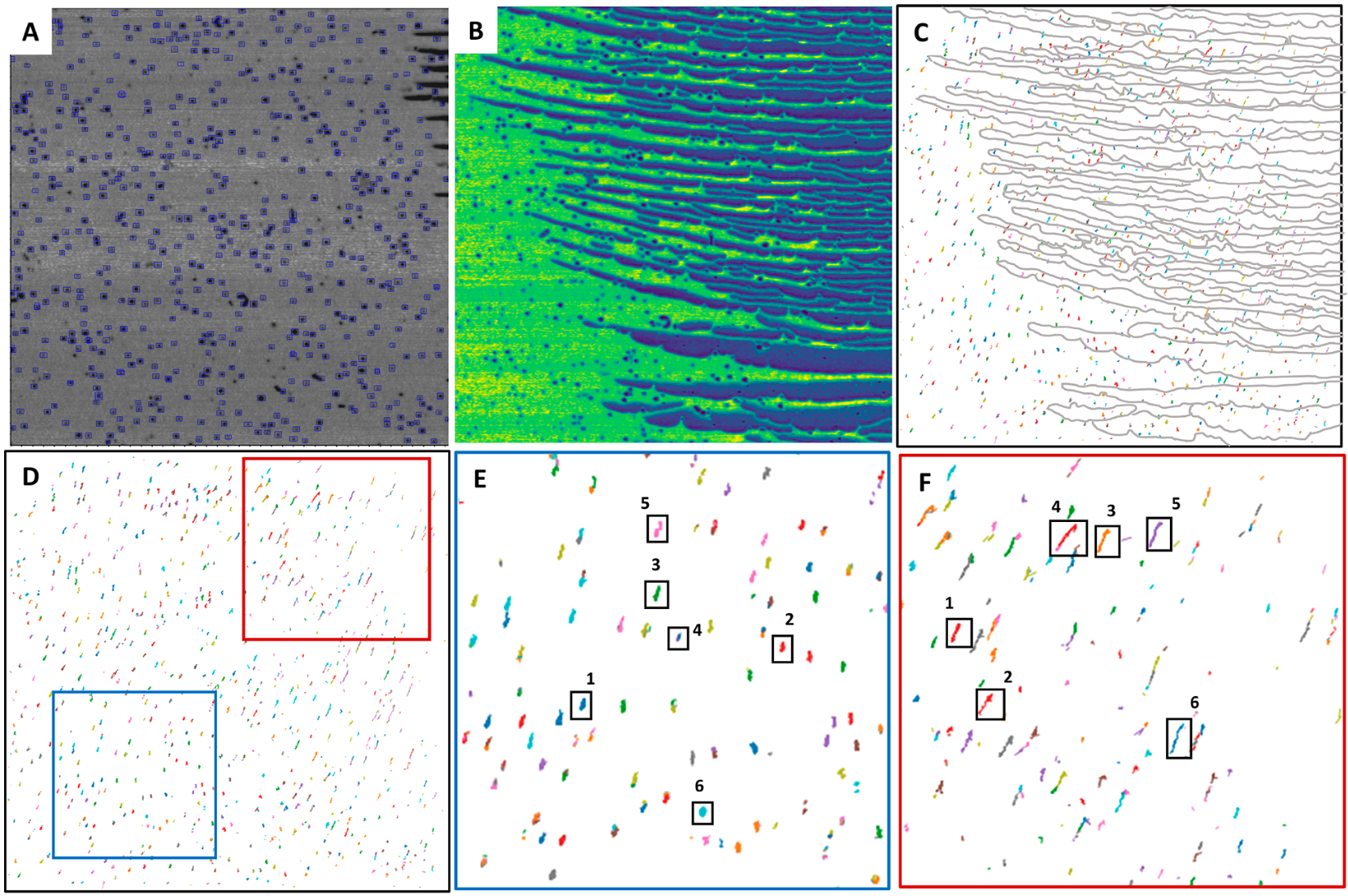
For simplicity, I use the 25th benchmark as the weights and modified it in the detect1.py file.
Example:
1
| python detect1.py --cut_size 100 --image_type tif --image_directory /home/yl768/UVM_H/images/46k_105C/2/ --output_type boxes --output /home/yl768/UVM_H/output/46K/
|

Trajectory
File: Track.ipynb
Usage: To find the trajectory of the particles using trackpy. A tutorial of trackpy can be found at http://soft-matter.github.io/trackpy/dev/tutorial/walkthrough.html.
You should be able to export the xls file like this.

References
Acknowlegements
This work was sponsored and supported by Prof. Kai Zhang. Eric Zhonghang Qu has given me tremendous support in my initial set-up of the environment. Kamlesh Bornani, PhD kindly provided the TEM images and shared many great insights with me.