Info
- Title: LLaMA-Omni 2: LLM-based Real-time Spoken Chatbot with Autoregressive Streaming Speech Synthesis
- Group: CAS
- Keywords: Speech LLM, streaming
- Venue: Submitted to EMNLP 2025
Comments
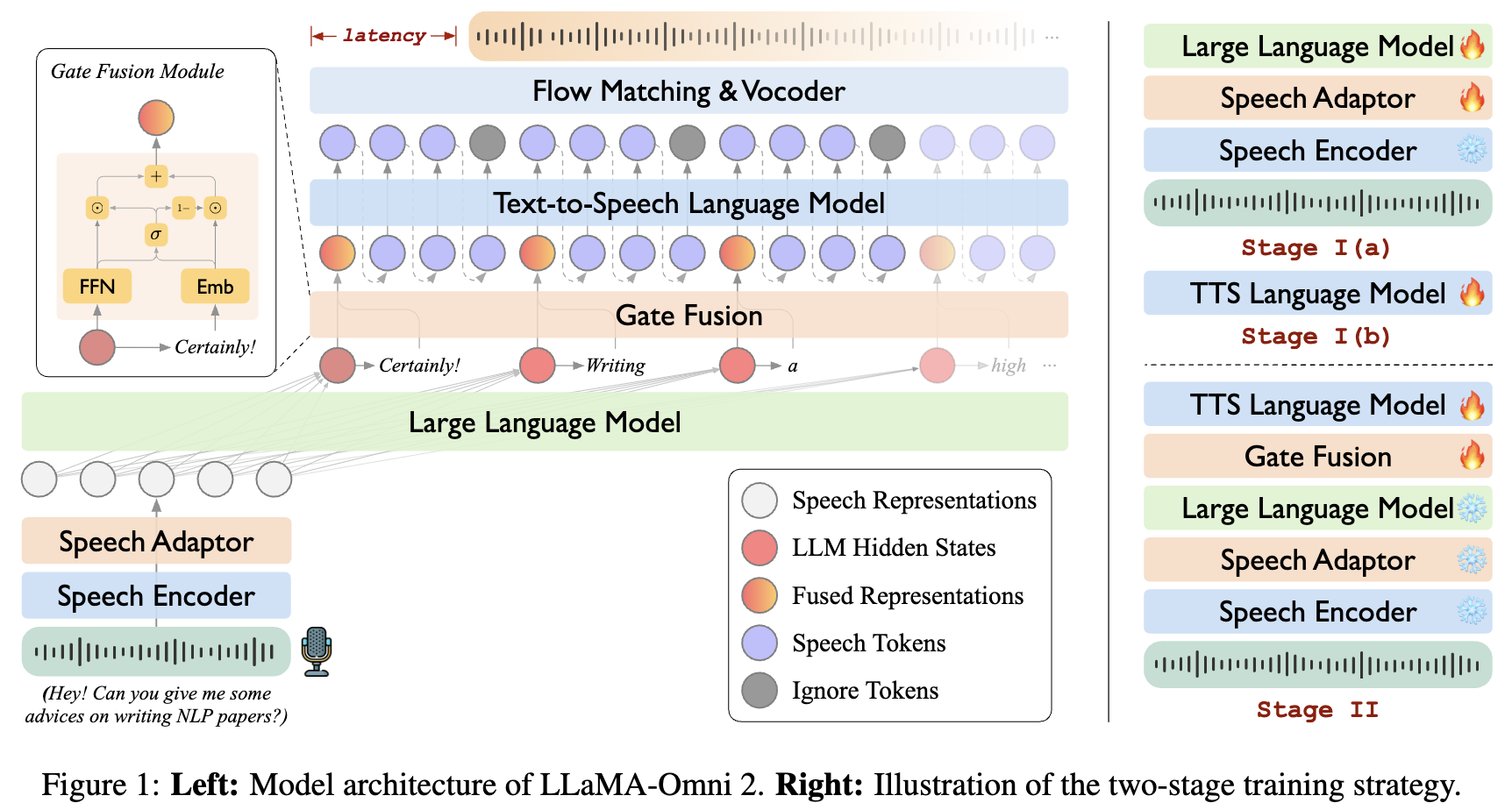
- Read and write: read and fuse from the text token, then generate the speech tokens corresponding to the text token.
- Use Qwen2.5-0.5B for model initialization.