Info
- Title: CAV-MAE Sync: Improving Contrastive Audio-Visual Mask Autoencoders via Fine-Grained Alignment
- Group: MIT
- Keywords: audio-visual, mask autoencoder, contrastive learning
- Venue: CVPR 2025
Comments
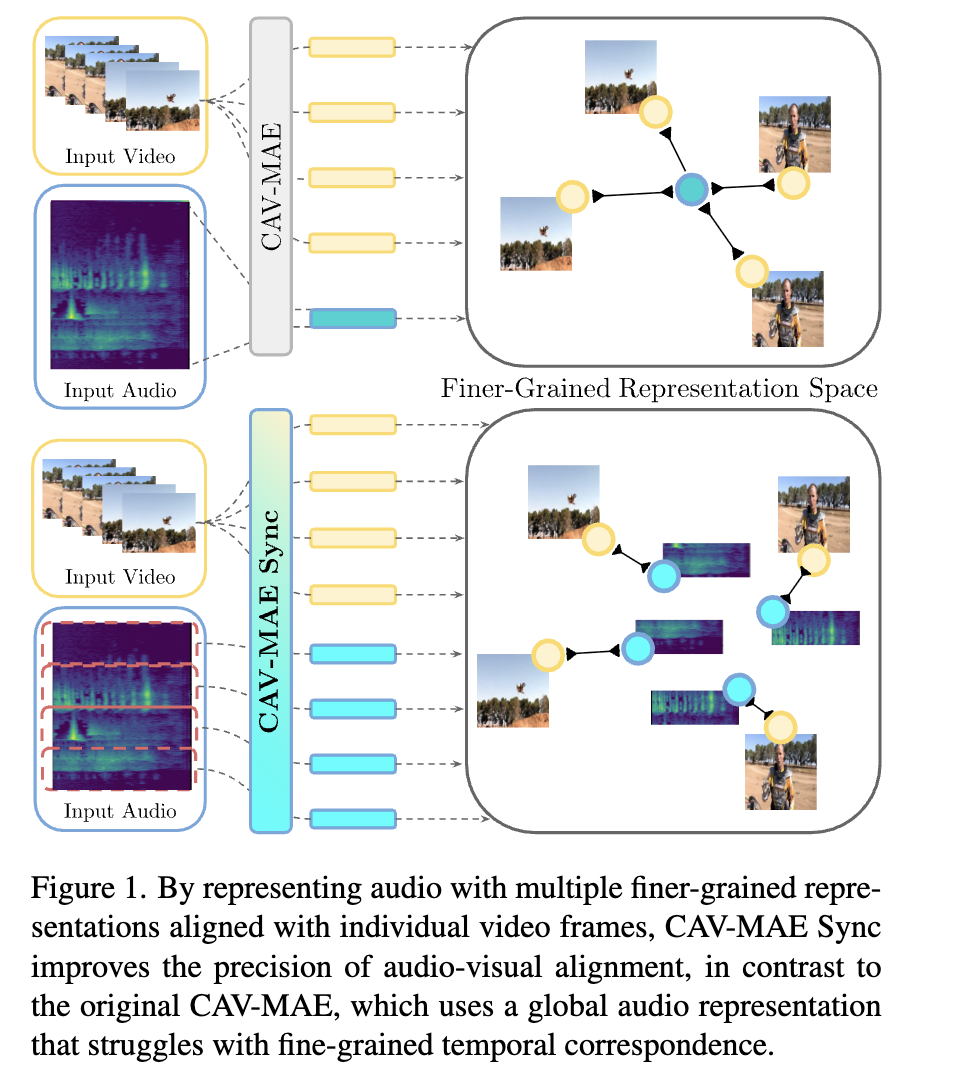
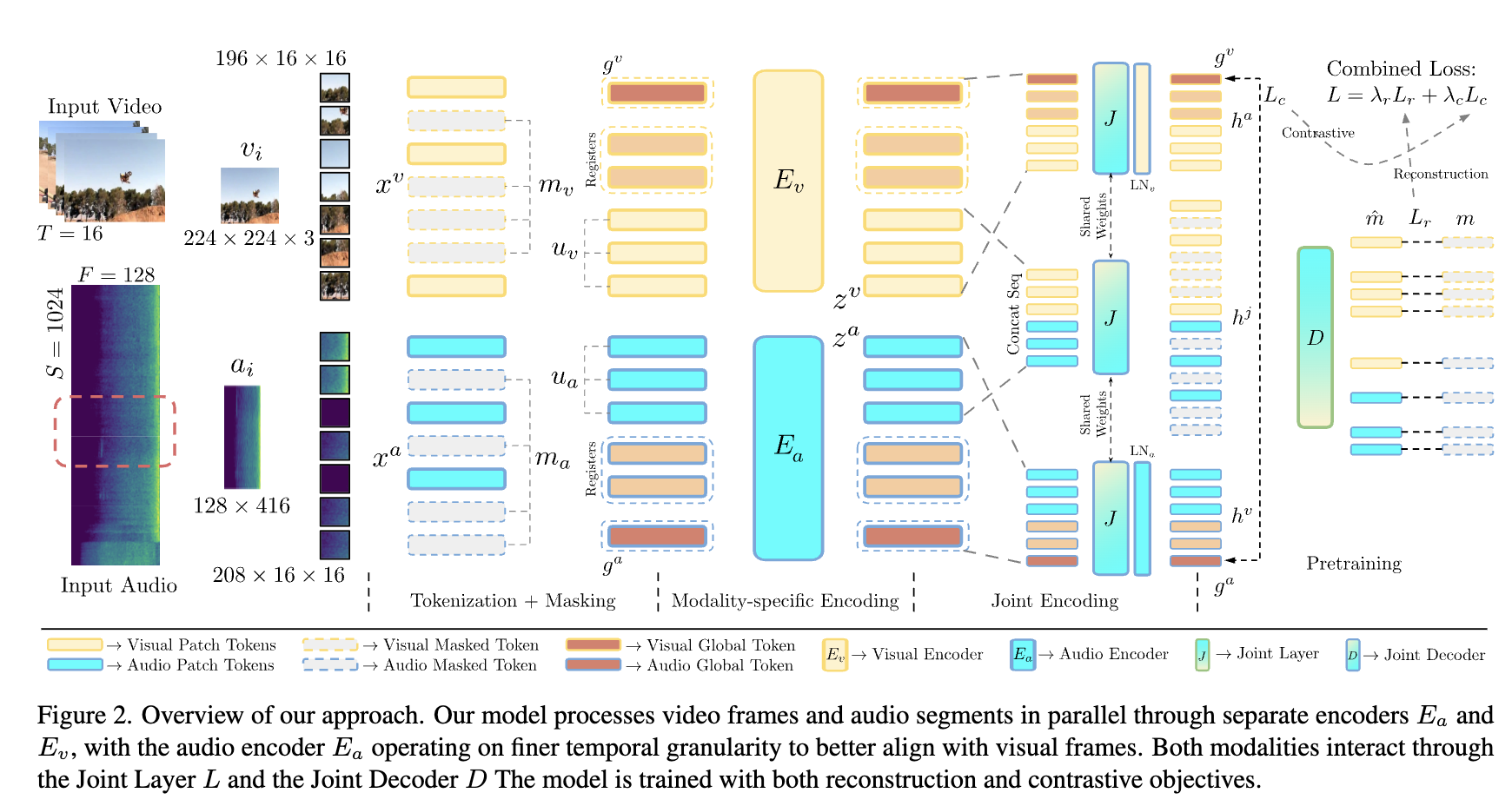
CAV-MAE Sync improves audio-visual learning by aligning audio temporally with video, separating contrastive and reconstruction objectives, and using register tokens for better spatial localization
Takeaways:
- For temporal alignment, it just split the audio and video in each frame correspondingly.
- It is not surprising that adding several “register tokens” can help improve the performance of the model.