Info
- Title: SVLTA: Benchmarking Vision-Language Temporal Alignment via Synthetic Video Situation
- Group: USTC
- Keywords: video-text retrieval, temporal alignment, synthetic video, benchmark
- Venue: arXiv
Comments
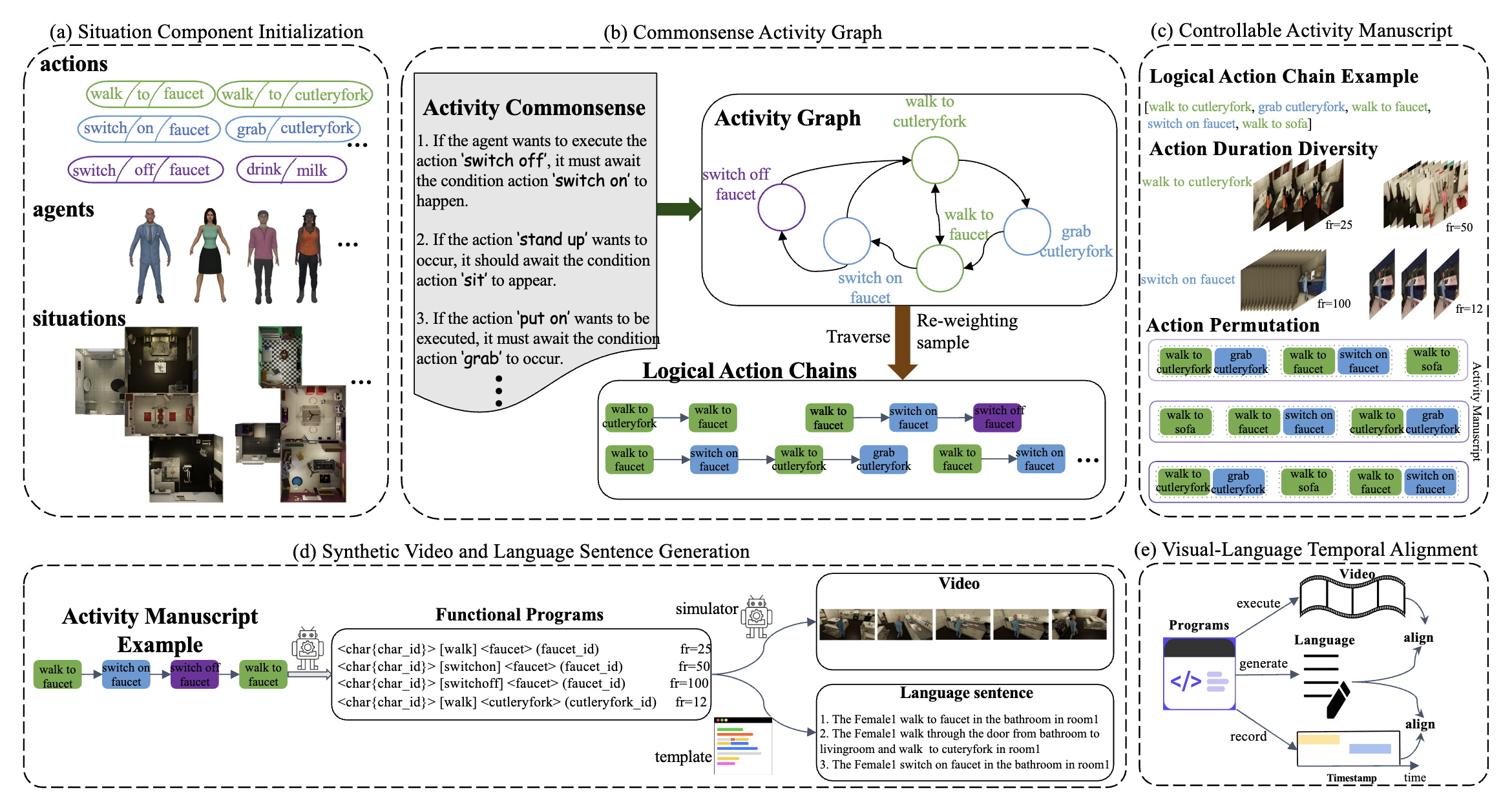
It uses VirtualHome to generate synthetic video-text pairs.