Info
- Title: Param Δ for Direct Weight Mixing: Post-Train Large Language Model at Zero Cost
- Group: Meta
- Keywords: training-free, weight mixing, large language model
- Venue: ICLR 2025
Comments
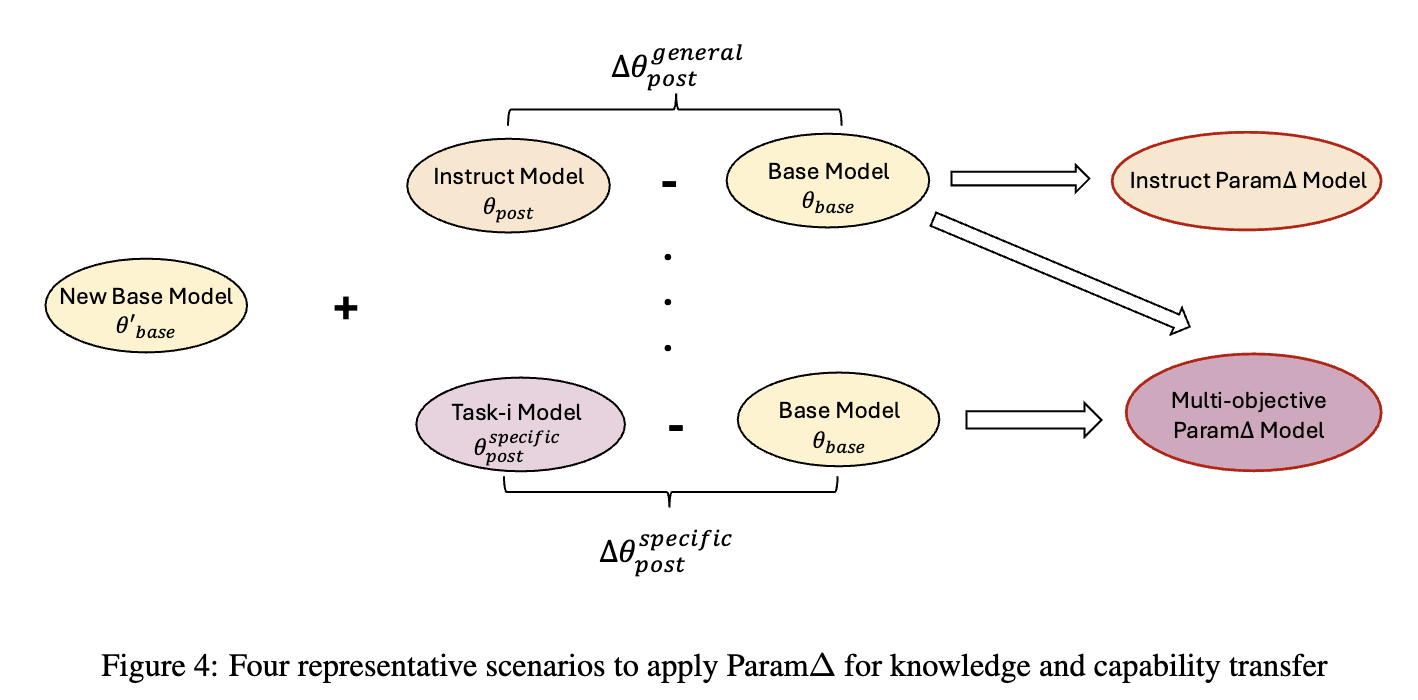
A new post-training method for large language model. It directly adds the weight difference (ΔΘ = Θpost - Θbase) to the new base model (ΘParamΔ = Θ′base + ΔΘ), achieving comparable performance without additional training.