Info
- Title: Kimi-Audio Technical Report
- Group: Kimi
- Keywords: audio llm
- Venue: arXiv
Comments
Use 13 million hours of audio, wow!
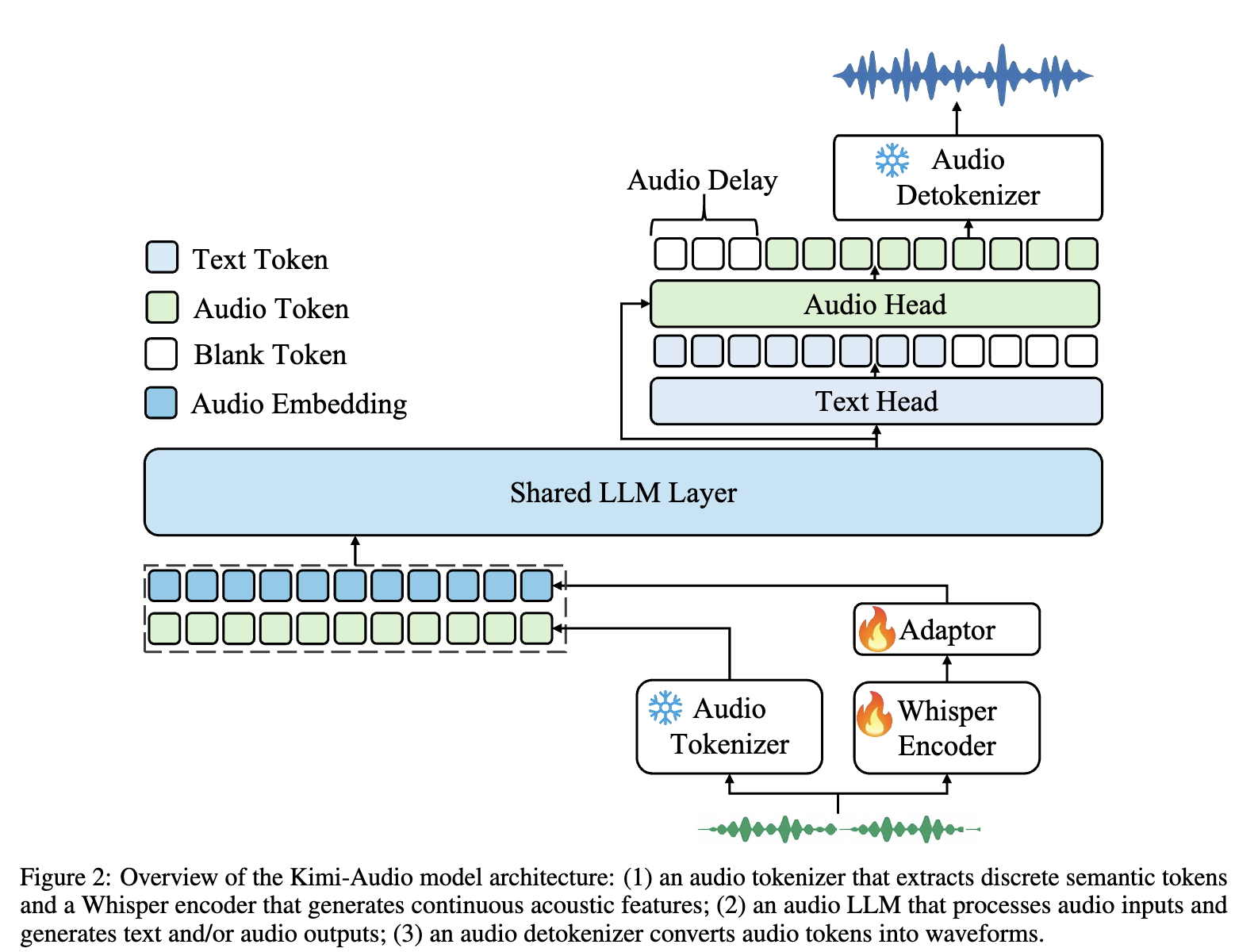
Audio delay (blank tokens) for subsequent audio generation.
They have open-sourced their evaluation kit.
Input: audio tokenizer (transform to discrete semantic tokens), Whisper encoder (extract continuous acoustic features) (added together)
Model: first few layers are shared, then have text head and audio head
Output: use “look-ahead” mechanism, take the future semantic tokens when generate the previous chunk, and only retain the previous chunk’s mel-spectrogram.
Suprised to see that Xu Tan is with Kimi team now.