Info
- Title: Memory-enhanced Retrieval Augmentation for Long Video Understanding
- Group: RUC
- Keywords: long video understanding
- Venue: ICCV Submission
Challenge
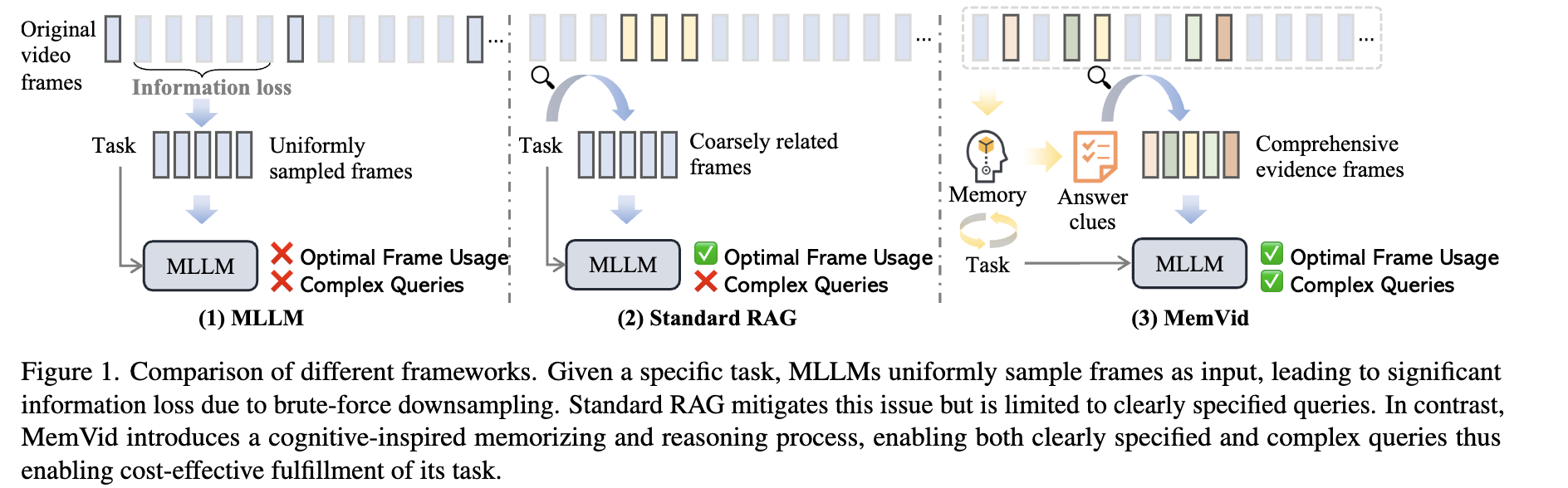
Long video understanding (LVU) presents significant challenges for multimodal large language models (MLLMs), mainly because these models were originally designed for shorter visual inputs. Current approaches to handle long videos face critical limitations:
Traditional MLLMs: Use uniform frame sampling, causing significant information loss through brute-force downsampling.
Standard Retrieval-Augmented Generation (RAG): While RAG can retrieve relevant moments from long videos, it struggles with implicit or complex queries that require contextual understanding rather than direct retrieval.
For example, a query like “What event is shared by two families as depicted in the video?” requires reasoning to identify families, track activities, and determine common events before retrieval can be effective.
Method
The authors propose MemVid, a memory-enhanced retrieval framework for long video understanding that mimics human cognitive processing. MemVid operates through four fundamental steps:
Memorizing: The system encodes the entire video into a structured memory representation to capture holistic information and long-range dependencies.
Reasoning: Using this memory, the system reasons about the query to infer latent information needs and generate explicit retrieval clues.
Retrieving: The system retrieves the most relevant video moments based on the generated clues.
Focusing: The downstream MLLM processes these retrieved moments along with the original query to produce the final answer.
To optimize the memorizer component, the authors implement a curriculum learning strategy:
- Supervised Fine-Tuning (SFT): Training on high-quality annotations from powerful MLLMs
- Reinforcement Learning: Further refining performance using Direct Preference Optimization (DPO) to align generated clues with downstream objectives
The retrieval process segments videos into fixed-duration moments rather than relying on dense captioning (which loses visual information) or frame-level approaches (which lose temporal context). This maintains both temporal and visual context in the retrieved content.
Results
MemVid was evaluated against various baselines on three long video understanding benchmarks:
- VideoMME (videos up to 60 minutes)
- MLVU (videos from 3 minutes to 2 hours)
- LVBench (extremely long videos with average duration of 4,101 seconds)
Key findings include:
MemVid established new state-of-the-art performance among 7B models on all benchmarks:
- 9.8% relative gain on MLVU compared to Qwen2VL
- 10.2% improvement on VideoMME without subtitles
- Outperformed leading context-extension method Video-XL by 15.3% on VideoMME
Compared to direct retrieval ($\text{RAG}_\text{simple}$), MemVid showed 5.8% improvement on MLVU and 3.9% improvement on VideoMME without subtitles.
MemVid was particularly effective for complex tasks requiring temporal understanding:
- 62.3% improvement in key information retrieval compared to Qwen2VL
- 38.3% improvement in key information retrieval compared to $\text{RAG}_\text{simple}$
Significant efficiency gains:
- Reduced input length by 93.8% (64 frames vs. 1024)
- Decreased GPU memory usage by 34.9%
- Reduced inference latency by 35.1%
- Still achieved 17.3% higher performance compared to Video-XL
MemVid showed generalization ability across different downstream MLLMs:
- 10.1% improvement with VILA-1.5 (3B)
- 3.5% improvement with LongVA (7B)
- 2.4% improvement with Qwen2VL (72B)
Insights
This paper offers several significant insights for long video understanding:
Cognitive-inspired approach: The human-like memory and reasoning process proves to be more effective than direct retrieval or uniform sampling. This suggests that mimicking human cognitive processes can lead to more powerful AI systems for complex multimedia tasks.
Decomposing complex queries: By breaking down complex queries into explicit retrieval clues, MemVid overcomes a fundamental limitation of traditional RAG systems that depend on clearly specified queries.
Curriculum learning benefits: The progression from supervised learning to reinforcement learning allows the system to first establish task understanding and then explore more diverse reasoning patterns, leading to better generalization.
Efficiency-performance tradeoff: MemVid demonstrates that selective frame sampling guided by semantic understanding is far more efficient than uniform sampling or simply extending context windows. With just 64 frames, it outperforms methods using 1024 frames.
Balance of global and local information: By combining retrieved moments (focused on query-relevant content) with uniformly sampled frames (preserving global context), MemVid maintains both detailed local information and broader video context.
Generalization across models: The approach shows improvements across models of different sizes, with smaller models benefiting more. This suggests that memory-enhanced retrieval can particularly benefit resource-constrained scenarios.
Comments
Could be the first to use congenitive memory to cope with long video comprehension. In MemVid, the memory model doesn’t generate embeddings but instead produces a set of textual sentences (typically 4 specific retrieval clues) that decompose the original query into explicit sub-questions, which are then used to guide the retrieval system in finding relevant video segments. After generating textual clues, MemVid identifies relevant video frames by computing embedding similarity between each clue and video segments using LanguageBind-Large as the cross-modal retriever, then selects the top-k most similar moments for each clue.
