Info
- Title: VACE: Video Tasks within an All-in-one Framework for Creation and Editing
- Group: Alibaba Group
- Keywords: video generation, video editing, video manipulation
- Venue: Preprint
Challenge
The authors address a significant challenge in the video generation field: creating a unified model capable of handling multiple video tasks. While unified models for image generation and editing have advanced rapidly, the video domain faces unique challenges due to the need for consistency across both temporal and spatial dimensions. Existing approaches typically use task-specific models, which leads to greater deployment costs and limits creative flexibility. The paper aims to develop a single model framework that can perform reference-to-video generation, video-to-video editing, masked video-to-video editing, and compositional combinations of these tasks.
Method
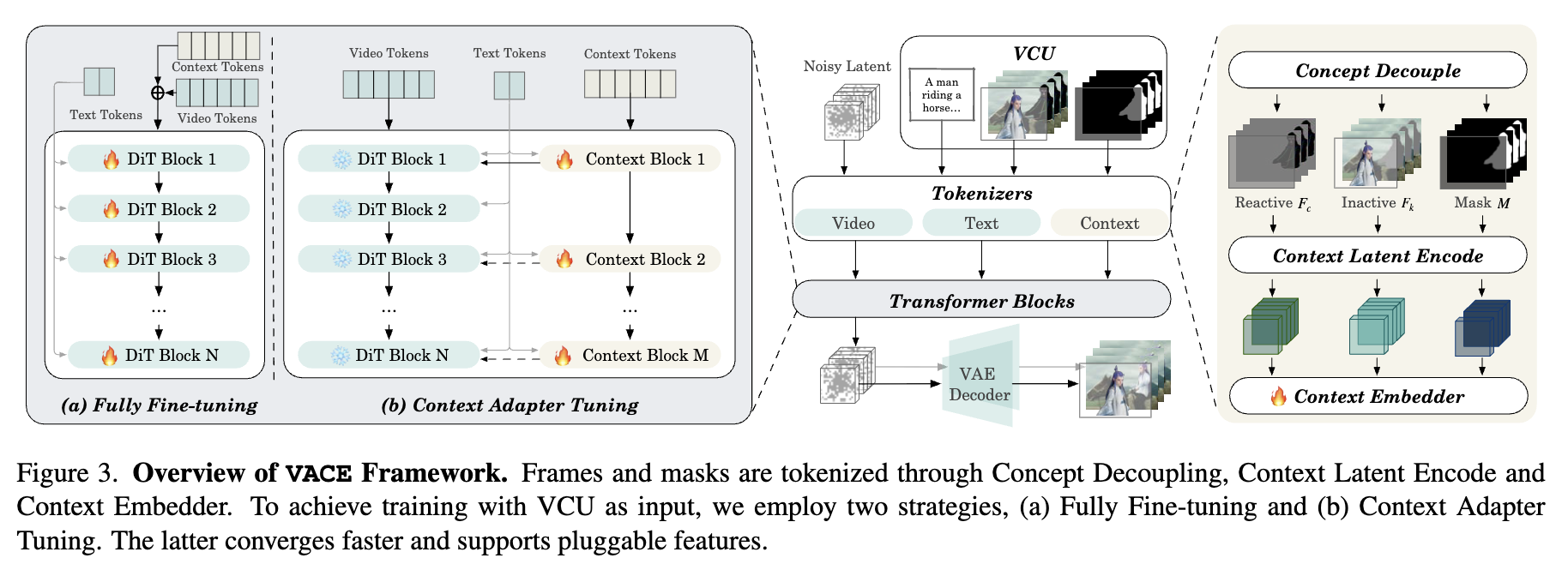
The authors introduce VACE (Video tasks within an All-in-one framework for Creation and Editing), which includes several key components:
Video Condition Unit (VCU): A unified input paradigm that organizes various inputs (text, image, video, mask) into a standardized format. This allows the system to handle different tasks through a consistent interface.
Concept Decoupling: A technique that separates visual inputs into “reactive frames” (pixels to be changed) and “inactive frames” (pixels to be kept), enabling the model to better understand what should be preserved versus modified.
Context Adapter: A structure that injects task-specific concepts into the model through spatiotemporal representation, allowing flexible handling of diverse video synthesis tasks.
Diffusion Transformer Architecture: The model builds upon existing Diffusion Transformers (DiTs) pre-trained for text-to-video generation, providing a strong foundation for handling long video sequences.
Two Training Strategies:
- Fully Fine-tuning the entire DiT model
- Context Adapter Tuning, which converges faster and allows for pluggable features
Results
The authors evaluated VACE against task-specific models on a custom benchmark (VACE-Benchmark) with 480 evaluation samples across 12 different tasks:
Quantitative Performance: VACE achieved comparable or superior performance to specialized models across multiple metrics, including aesthetic quality, background consistency, motion smoothness, and temporal flickering.
User Study: Human evaluations confirmed VACE’s strong performance in prompt following, temporal consistency, and video quality.
Task Coverage: The model successfully handled diverse tasks including:
- Reference-to-video generation (using faces, objects, or frames as reference)
- Video-to-video editing (colorization, stylization, controllable generation)
- Masked video-to-video editing (inpainting, outpainting, extension)
- Compositional tasks combining multiple capabilities
Ablation Studies: The authors demonstrated the effectiveness of their design choices through ablation studies on the base structure, context adapter configuration, and concept decoupling.
Insights
Unified Architecture Efficiency: The research demonstrates that a single model can effectively handle diverse video generation and editing tasks without significant performance degradation compared to specialized models, reducing deployment costs and simplifying user workflows.
Compositional Power: One of VACE’s most significant contributions is enabling task composition (e.g., “Move Anything” by combining reference generation with motion control), which opens entirely new creative possibilities not achievable with existing single-task models.
Implementation Balance: The paper highlights the trade-off between model size and generation speed, showing that while larger models (like Wan-T2V-14B) produce higher quality results, smaller models (like LTX-Video-2B) offer faster generation for practical applications.
Future Directions: The authors acknowledge limitations in maintaining identity during reference generation and achieving complete control in compositional tasks, suggesting these as areas for future improvement with larger-scale training.
Social Impact Awareness: The authors demonstrate thoughtfulness about both positive applications (creative tools, marketing, advertising) and potential misuse concerns (misinformation, bias reinforcement), suggesting a balanced approach to developing this technology.
Comments
Essentially, VCU is a standardized input paradigm that organizes various inputs (text, image, video, mask) where $V=[T;F;M]$.
