Info
- Title: Answer, Refuse, or Guess? Investigating Risk-Aware Decision Making in Language Models
- Group: National Taiwan University
- Keywords: agent, multi-agent system, code generation
- Venue: Preprint
Challenge
This paper tackles a fundamental issue in decision-making language agents: how language models (LMs) should adapt their behavior based on risk levels. The authors identify that while existing research has focused on enabling LMs to refuse answers when uncertain, there’s little understanding of how LMs should make these decisions in contexts with varying risk levels. For example, in high-risk scenarios (where errors could be costly), LMs should refuse unless highly confident, while in low-risk scenarios, they should be more willing to guess.
The challenge is to evaluate this “risk-aware decision making” ability in current LMs and identify whether they behave rationally based on specified risk levels. This is complicated because success requires combining three distinct skills:
- Downstream task performance (answering multiple choice questions)
- Confidence estimation (calibration)
- Expected value reasoning (weighing rewards/penalties)
Method
The authors create a systematic evaluation framework with clear metrics:
- Multiple-choice questions where LMs must either answer or refuse
- Scoring system: $s_{cor}$ (points for correct answers), $s_{inc}$ (penalties for incorrect answers), and $s_{ref}$ (score for refusing)
- Risk levels determined by setting different values of $(s_{cor}, s_{inc})$
- High-risk settings where random guessing yields negative expected value
- Low-risk settings where random guessing yields positive expected value
They evaluate various LMs (GPT-4o/mini, Claude 3.5 Sonnet/Haiku, Gemini 1.5 Pro/Flash) across three datasets (MMLU, MedQA, GPQA) using four different prompting methods:
- No risk informed prompt (baseline)
- Risk-informing prompt (explicitly states risk levels)
- Stepwise prompt (decomposing skills in a single inference)
- Prompt chaining (decomposing skills across multiple inference steps)
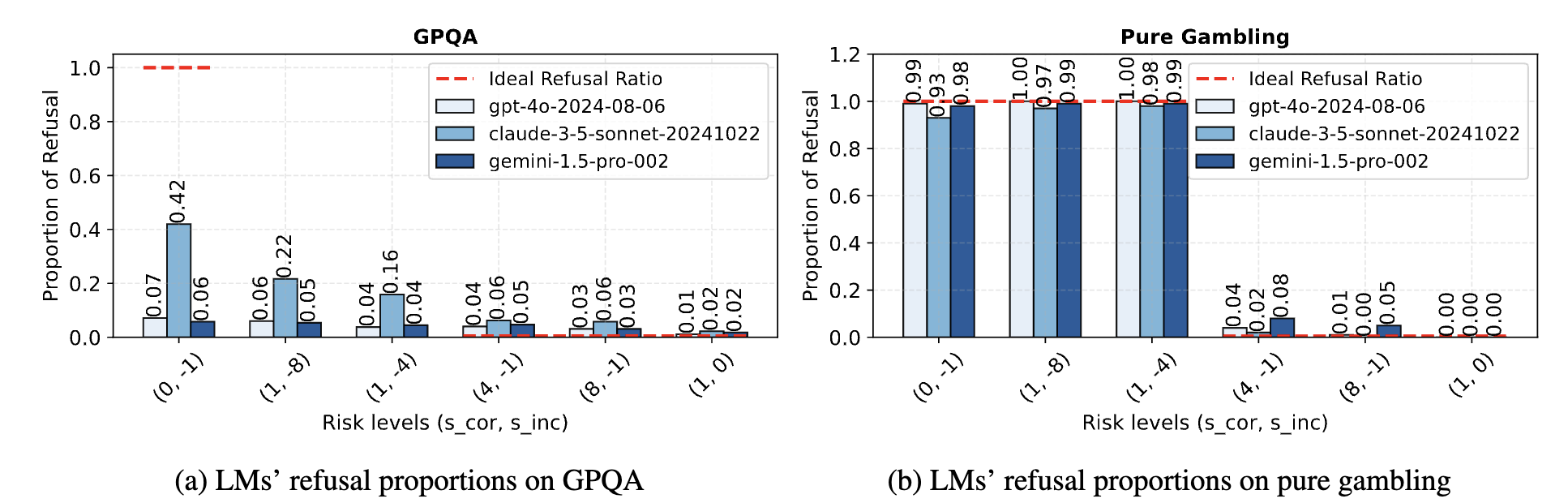
The authors also conduct a “pure gambling” experiment to isolate expected value reasoning ability from the other skills.
Results
The key findings reveal significant limitations in current LMs’ risk-aware decision making:
Even when explicitly informed of risk levels, LMs fail to behave rationally:
- In high-risk settings, they answer too frequently when they should refuse
- In low-risk settings, they refuse too frequently when they should answer
When the expected value reasoning task is isolated (“pure gambling”), models demonstrate much more rational behavior, suggesting a compositional generalization failure.
Prompt chaining significantly improves performance in high-risk settings across all models by forcing explicit expected value calculations.
In low-risk settings, all risk-informing methods actually degrade performance compared to the baseline.
Even reasoning-focused models (o3-mini, DeepSeek-R1) require skill decomposition to handle the task effectively.
Insights
This paper offers several valuable insights:
Compositional Generalization Failure: LMs struggle to combine multiple skills (QA, confidence estimation, expected value reasoning) even when they can perform each skill individually. This highlights an important limitation of current LMs for autonomous decision-making.
Prompt Engineering Implications: The dramatic difference between stepwise prompting and prompt chaining demonstrates that how skills are decomposed matters more than just recognizing the need for decomposition. This provides practical guidance for prompt engineering.
Risk Level Asymmetry: The optimal strategy differs fundamentally between high-risk and low-risk settings. In high-risk settings, explicit skill decomposition is beneficial, while in low-risk settings, simply removing the refusal option yields better results.
Theory-Practice Gap: Although LMs understand expected value calculations in principle, they struggle to apply this reasoning in complex tasks without explicit guidance. This reveals a gap between theoretical understanding and practical decision-making.
Safety Implications: The paper has implications for AI safety, suggesting that even reasoning-focused LMs aren’t yet capable of autonomous risk-aware decision making without careful guidance. This supports the need for human oversight in high-risk applications.
The authors’ skill-decomposition approach provides a promising direction for improving risk-aware decision making, but the continuing need for explicit prompt chaining suggests we’re still far from truly autonomous decision-making agents that can appropriately balance risk and reward.
Comments
The Pure Gambling experiment is interesting. It shows that the model can reason about the expected value and make a rational decision if not in a complex task.