Info
- Title: Talking Turns: Benchmarking Audio Foundation Models on Turn-Taking Dynamics
- Group: CMU, Apple
- Keywords: audio foundation model, benchmark
- Venue: ICLR 2025
Challenge
Audio foundation models (FMs) have shown promise for conversational AI, but there’s been limited evaluation of how well they handle the natural flow of conversation—specifically turn-taking dynamics. Unlike written dialogue, spoken conversation requires careful management of turns, with speakers knowing when to speak, when to listen, and how to handle overlapping speech and silences. The authors focus on three key aspects of turn-taking that audio FMs should master:
- Understanding turn-taking events (recognizing patterns in human conversation)
- Predicting turn-taking events (anticipating when turns should change)
- Performing turn-taking events (executing natural turn exchanges in real-time)
The paper aims to create a comprehensive evaluation framework for these capabilities, as existing metrics only measure basic statistics like overlap frequency rather than the quality and timing of conversational exchanges.
Method
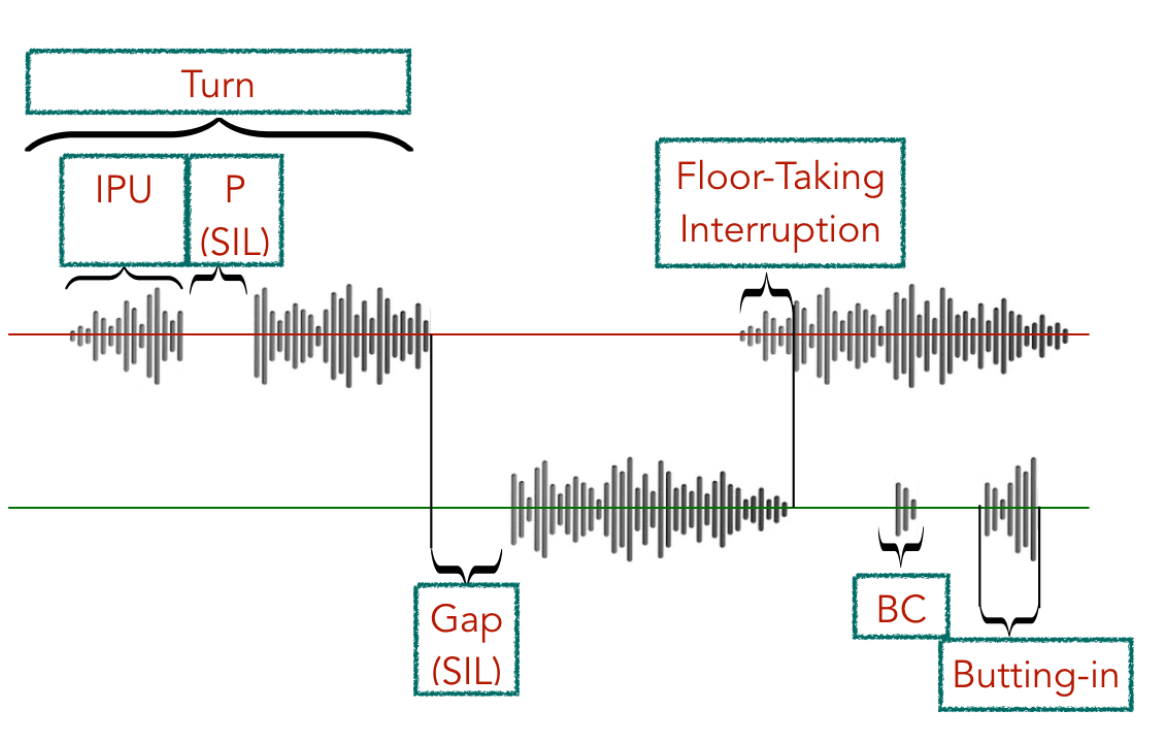
The authors developed a novel evaluation approach with several key components:
Supervised Turn-Taking Judge Model: They trained a model on human-human conversations to predict turn-taking events including:
- Turn changes (when speaker shifts occur)
- Backchannels (acknowledgment sounds like “mm-hmm”)
- Interruptions (overlapping speech to take the floor)
- Continuation (ongoing speech by same speaker)
Core Conversation Capabilities Framework: They identified five essential turn-taking abilities:
- When the system should speak up during user pauses
- When the system should provide backchannels
- When the system should interrupt
- How the system conveys to users when they can speak
- How the system handles user interruptions
Evaluation Protocol: For each capability, they created metrics that compare AI decisions against the judge model’s recommendations, measuring how closely the AI’s turn-taking behavior matches human-like patterns.
User Study: They collected 4+ hours of human conversations with two systems:
- Moshi: A full-duplex end-to-end spoken dialogue system
- A cascaded system using separate components for VAD, ASR, LLM, and TTS
Additional Benchmarks: They also evaluated several audio FMs (SALMONN, Qwen-Audio models, Whisper+GPT-4o) on their ability to understand and predict turn-taking using curated test scenarios.
Results
The evaluation revealed significant limitations in current audio FMs:
For Moshi (end-to-end system):
- Sometimes fails to speak up when users are ready to yield their turn
- Interrupts too aggressively and at inappropriate moments
- Rarely produces backchannels to acknowledge user speech
- Doesn’t give users clear cues about when it wants to keep speaking
- Usually continues speaking even when interrupted by users
For the cascaded system:
- Worse at deciding when to speak up or allow users to continue
- Shows higher latency with large gaps between turns
- Almost never backchannels or interrupts
- Slightly better at conveying turn willingness than Moshi
- More likely to yield when interrupted (but interruptions rarely occur)
For understanding and predicting turn-taking:
- Most models performed close to random guessing on backchannel prediction
- Qwen-Audio-Chat showed better performance understanding interruptions
- Whisper+GPT-4o excelled at predicting turn changes but struggled with other events
- All models showed substantial room for improvement
Insights
This study provides several important contributions to conversational AI research:
New Evaluation Framework: The authors developed the first comprehensive protocol for evaluating turn-taking in audio FMs, going beyond simple metrics to assess the quality and timing of conversational interactions.
Detailed Diagnosis: The work identifies specific weaknesses in current systems that weren’t apparent from previous evaluation methods. For example, corpus-level statistics showed Moshi had overlapping speech similar to humans, but the new metrics revealed these interruptions were poorly timed and disruptive.
Design Implications: The authors offer concrete suggestions for improvement:
- For Moshi: Adjusting EPAD/PAD logit biases when users pause or interrupt
- For both systems: Increasing fine-tuning on speech conversations to improve backchanneling
- For cascaded systems: Implementing more sophisticated turn-taking than just silence detection
Benchmark Resources: The evaluation platform will be open-sourced to help researchers assess and improve their models, potentially accelerating progress in this area.
The research demonstrates that building truly conversational AI requires more than just accurate ASR and response generation—it needs sophisticated turn management capabilities that current systems largely lack. The paper establishes both the importance of this problem and a framework for addressing it systematically.
Comments
I was suprised to see an evaluation benchmark can be accepted by ICLR. I saw the reviews on OpenReview and the revierers are concerned about the rationale of selecting certain thresholds and biased participants involved.
Regarding benchmark, I think it would be nice to identify meaningful gaps and build on theoretical foundations, as well as create multi-dimensional metrics.
Regrading storytelling, structure findings as insights is a good practice. And connect evaluation to improvement, and use clear visualizations.
For the dataset, they use Switchboard, which is a corpus of conversational telephone speech (260 hours, 543 speakers).