Info
- Title: Why Is Spatial Reasoning Hard for VLMs? An Attention Mechanism Perspective on Focus Areas
- Group: Northwestern University
- Keywords: spatial reasoning, vision language model, attention
- Venue: Submitted to ICML 2025
Challenge
This paper addresses a significant limitation in Large Vision Language Models (VLMs): their poor performance on spatial reasoning tasks. Despite advances in object recognition, VLMs struggle with basic spatial relationships like “left,” “right,” “above,” “below,” “behind,” or “in front of.” The authors investigate this problem through mechanistic interpretability, analyzing how vision and text tokens interact within the model’s internal states.
Key challenges identified:
- Despite image tokens comprising ~90% of input sequences, they receive only ~10% of the model’s attention
- Simply increasing overall attention to image tokens doesn’t improve performance
- The model’s attention distribution often doesn’t align with actual object locations
- VLMs struggle more with certain spatial relationships (like “on” and “under”) than with others (like “left” and “right”)
Method
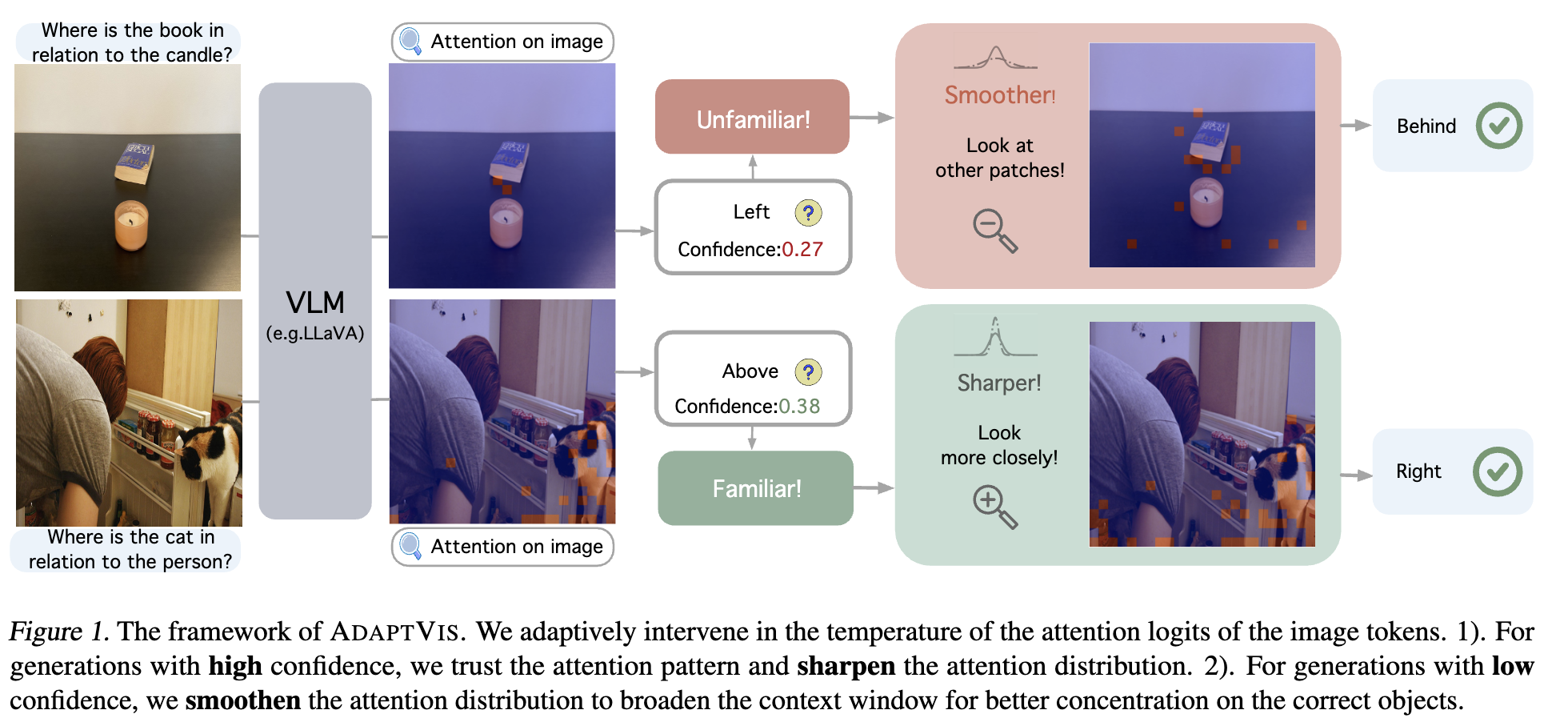
The authors propose AdaptVis, a training-free decoding method that dynamically adjusts attention distribution based on the model’s confidence level:
Core insight: When the model exhibits high confidence (measured by generation probability), attention should be sharpened to focus on relevant regions. When confidence is low, attention should be smoothed to explore a wider context.
Implementation:
- First analyzed where attention is placed through intermediate layers using YOLO annotations
- Discovered that middle layers (especially 17th-18th) show strongest correlation between attention patterns and answer correctness
- Developed a temperature scaling method (ScalingVis) to modify attention distribution by multiplying attention logits by coefficient α
- Extended this into AdaptVis by making α adaptive based on confidence:
- When confidence < threshold $β$: Apply $\alpha_1 < 1$ (smoothing)
- When confidence > threshold $β$: Apply $\alpha_2 > 1$ (sharpening)
Dataset adaptation: Reformatted existing spatial reasoning datasets (WhatsUp, VSR) into QA format to evaluate generative models
Results
The proposed methods achieved significant improvements across spatial reasoning benchmarks:
- AdaptVis improved accuracy by up to 50 absolute percentage points over baseline
- ScalingVis (non-adaptive version) showed strong but less consistent improvements
- For synthetic images with clean backgrounds:
- Smoothing attention ($\alpha < 1$) was more effective
- Largest improvements seen in “set accuracy” (correct identification of all relationships in a set)
- For real-world images with complex backgrounds:
- Sharpening attention ($\alpha > 1$) was more effective
- Consistent improvements across COCO and Visual Genome datasets
Notably, the method revealed different patterns based on familiarity:
- For familiar relationships (“left”/“right”), the model benefited from sharpened attention
- For less familiar relationships (“on”/“under”/“behind”/“front”), it benefited from smoothed attention
Insights
The paper provides several key mechanistic insights about VLMs:
Attention imbalance: VLMs fundamentally underutilize visual information, with most attention focused on text tokens despite images comprising the majority of input
Geometric understanding: Successful spatial reasoning depends on the model’s ability to align attention with actual object locations, not just the amount of attention given to images
Familiarity effects: VLMs demonstrate higher confidence and better performance on more commonly represented spatial relationships in training data (“left”/“right”) than on less common ones
Confidence as a signal: The model’s confidence score serves as a reliable indicator of whether its attention pattern is trustworthy, enabling adaptive intervention
Attention adjustment mechanism: For unfamiliar cases, broadening attention helps the model consider alternative spatial interpretations; for familiar cases, narrowing attention reinforces correct spatial understanding
The authors demonstrate that simple, targeted interventions in attention mechanisms can dramatically improve spatial reasoning capabilities without retraining or fine-tuning, suggesting opportunities for similar approaches in other vision-centric tasks.
Comments
By monitoring the model’s confidence (generation probability) on spatial relationship tokens, AdaptVis dynamically adjusts attention distribution: smoothing it ($\alpha < 1$) when confidence is low to encourage broader image exploration, and sharpening it ($\alpha > 1$) when confidence is high to focus precisely on relevant regions. This approach recognizes that VLMs perform unevenly across different spatial relationships due to training data biases, effectively helping models “second-guess” themselves when uncertain and “double down” when confident. The impressive performance gains (up to 50 percentage points) with negligible computational overhead make this approach particularly valuable