Info
- Title: OPTISHEAR: Towards Efficient and Adaptive Pruning of Large Language Models via Evolutionary Optimization
- Group: CUHK
- Keywords: pruning, large language model
- Venue: Submitted to ACL 2025
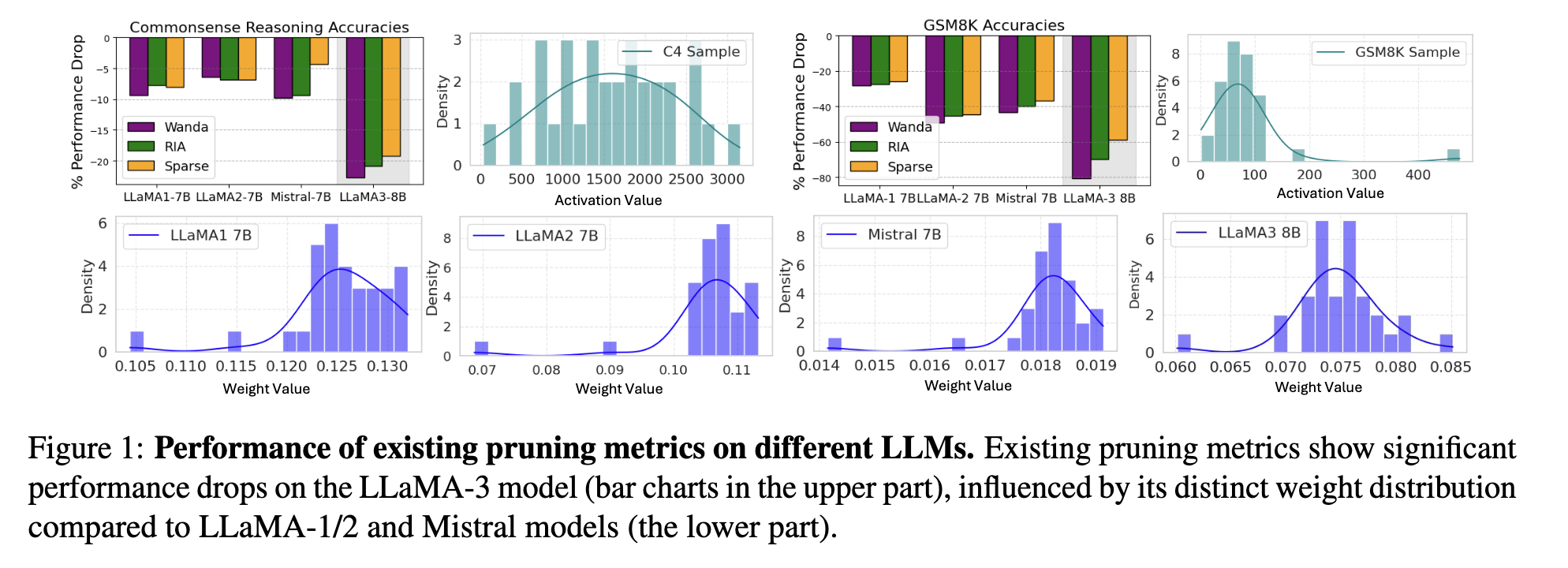
Challenge
The paper addresses a significant challenge in model compression for Large Language Models (LLMs): existing pruning methods that work well on some models (like LLaMA-1/2) perform poorly on newer models like LLaMA-3. The authors demonstrate this is due to different weight distributions across model families. Fixed pruning metrics fail to adapt to these distribution differences, leading to significant performance drops when applied to models with different architectures.
Method: OptiShear

Meta Pruning Metric Search
- Creates a flexible pruning metric: $S_{ij} = \alpha F_{1}(|W_{ij}|) \cdot \beta F_{2}(|X_{j}|_{2})$
- Where $W_{ij}$ is weight magnitude, $X_j$ is input activation norm
- $\alpha$, $β$ are coefficients and $F_{1}$, $F_{2}$ are transformation functions
- These elements are automatically customized for each model architecture
Layerwise Sparsity Ratio Search
The layerwise sparsity ratio search works as follows:
Search Space Definition:
- For each layer, the algorithm selects one of three possible sparsity ratios:
- $\text{target sparsity} - \text{sparsity step}$
- $\text{target sparsity}$
- $\text{target sparsity} + \text{sparsity step}$
- The target sparsity (e.g., 50%) is the overall pruning goal
- The sparsity step (e.g., 5% based on their ablation studies) allows for fine-tuned adjustments
- For each layer, the algorithm selects one of three possible sparsity ratios:
Multi-Objective Optimization:
- The search minimizes two objectives simultaneously:
- Model-wise reconstruction error: $f_{rec}(\theta, \theta^{*}) = |W_{l}X_{l} - (M_{l} \odot W_{l})\cdot X_{l}|_{Frob}$
- Sparsity ratio discrepancy: $f_{ratio}(\theta, \theta^{*}) = |R_{d} - \frac{\text{p}(\theta) - \text{p}(\theta^{*}|\mathcal{R})}{\text{p}(\theta)}|$
- Where $R_d$ is the pre-defined target sparsity, $\mathcal{R}$ represents the layerwise sparsity ratios, and $\text{p}(\cdot)$ counts the total parameters
- The search minimizes two objectives simultaneously:
Search Algorithm:
- Uses NSGA-III to find Pareto-optimal solutions
- The algorithm maintains a population of candidate solutions and evolves them over generations
- For each generation, it performs:
- Non-dominated sorting to rank solutions
- Selection based on Pareto dominance and diversity
- Genetic operations like crossover and mutation
Implementation Details:
- Empirically, they found that a discrete set of 3 sparsity ratios works best for LLMs with more than 32 layers
- The sparsity step of 5% yielded better results than smaller (3%) or larger (8-10%) steps
- From their ablation studies, upper layers typically receive higher sparsity ratios (more pruning) than lower layers
Results
OptiShear consistently outperforms all baseline pruning methods across multiple LLM families:
- Most impressive improvements are on LLaMA-3, where it achieves 41.17% accuracy on GSM8K compared to the previous best of 21.46%
- The layerwise sparsity ratio search improves performance for other metrics too:
- Wanda with OptiShear’s ratios: up to 16.49% relative improvement
- RIA with OptiShear’s ratios: up to 12.58% relative improvement
Insights
Non-uniform Layer Importance: The results in Table \ref{tab:ratio} and Figure \ref{fig:layerwise_ratio} confirm that upper layers of LLMs contain more redundant parameters than lower layers, supporting the effectiveness of non-uniform pruning.
Sparsity Step Selection: Their ablation studies show that a 5% sparsity step achieves the best balance - smaller steps don’t significantly reduce redundancy, while larger steps might overly simplify layers.
Search Efficiency: For models with 32+ layers, using just three discrete sparsity options yields better results than larger sets when operating under limited search trials.
The adaptive layer-specific pruning ratios represent a significant contribution, as they not only enhance OptiShear but also substantially improve existing methods like Wanda and RIA.
Comments
The “adaptive” part of OptiShear is quite intuitive. The reconstruction error measures the difference between the pruned model and the unpruned original model’s outputs, which provides a direct evaluation of how well the pruning strategy preserves model behavior. Meanwhile, the meta search method cleverly leverages weight magnitude and input activations, dynamically adjusting their relationship based on each model’s unique weight distribution patterns.