Info
- Title: Knowledge Bridger: Towards Training-Free Missing Modality Completion
- Group: Beijing Jiaotong University, Singapore Management University
- Keywords: training-free, knowledge transfer, multi-modal learning
- Venue: CVPR 2025
Challenge
This paper addresses the problem of Missing Modality Completion (MMC) in multimodal learning, which is crucial when real-world applications encounter incomplete data due to factors like sensor failures or privacy constraints. The authors identify two key limitations of existing approaches:
- Current MMC methods rely on carefully designed fusion techniques and extensive pre-training on complete data
- These methods have limited generalizability in out-of-domain (OOD) scenarios
The central research question posed is: “Can we develop a missing modality completion model that is both resource-efficient and robust to OOD generalization?”
Method
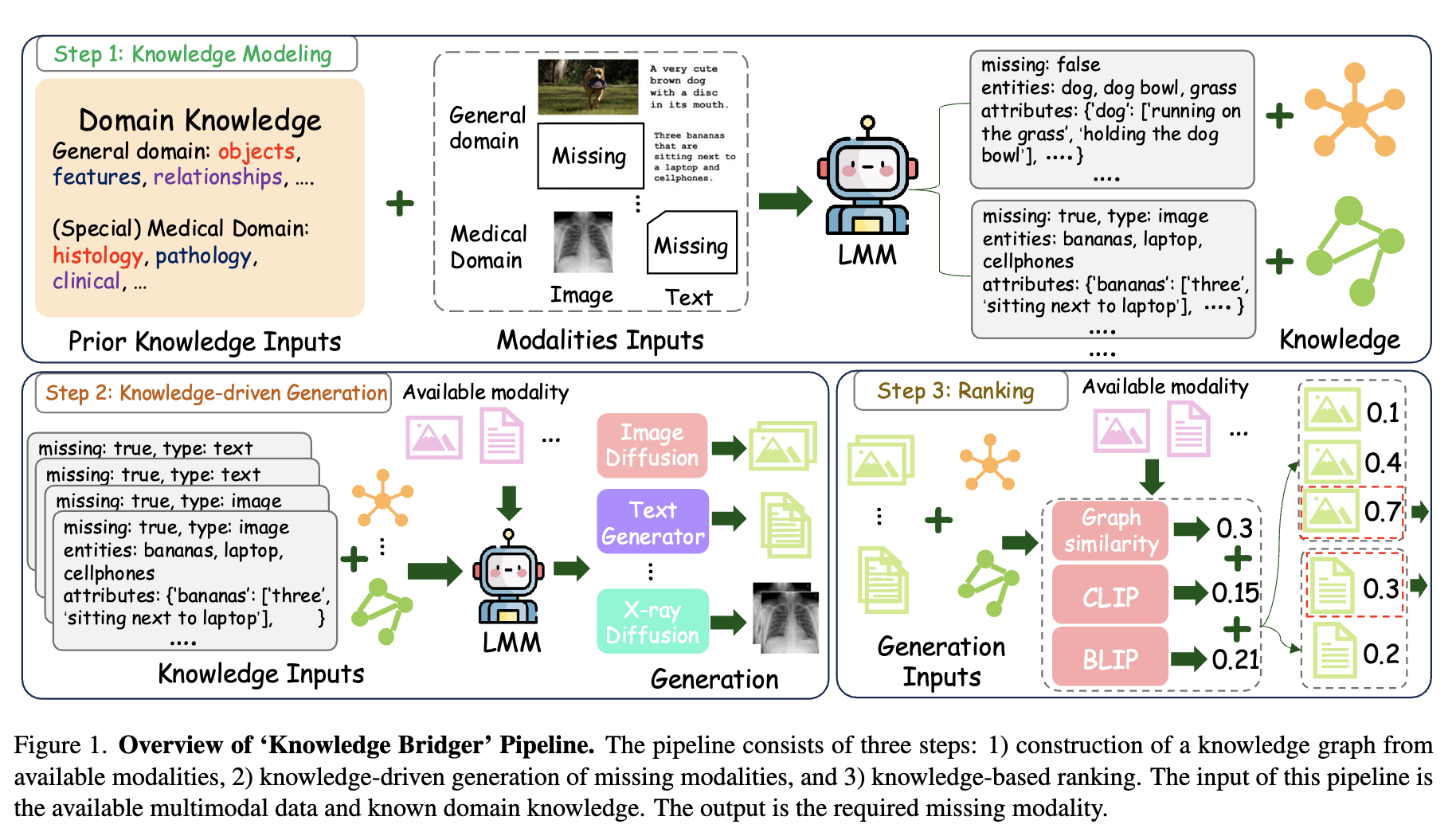
The authors propose “Knowledge Bridger,” a novel training-free framework for MMC that leverages Large Multimodal Models (LMMs). The approach consists of three main components:
Knowledge Graph Modeling:
- Uses LMM to extract structured information from available modalities
- Applies Chain-of-Thought reasoning to identify entities, relationships, and attributes
- Constructs knowledge graphs to represent the content’s structure
Knowledge-driven Generation:
- Utilizes the knowledge graphs to guide generation of missing modalities
- For missing images: uses extracted descriptions to guide diffusion models
- For missing text: uses LMM to generate descriptions based on image content
- Generates multiple candidates (5 by default)
Knowledge-based Ranking:
- Scores generated candidates using two similarity metrics:
- Graph similarity: compares knowledge graph structures
- Representation similarity: uses models like CLIP and BLIP to compare embeddings
- Selects the candidate with the highest combined score
- Scores generated candidates using two similarity metrics:
Results
The authors evaluated their approach on general domain datasets (COCO-2014, MM-IMDb) and a medical domain dataset (IU X-ray):
- Their method consistently outperformed competing methods on F1, mAP, and similarity metrics
- The approach showed particularly strong performance on the OOD medical dataset
- Performance improved with larger model sizes (from 2B to 7B to 72B parameters)
- The method showed increasing advantages at higher missing rates (0.7)
Insights
Key insights from the paper include:
Knowledge extraction is critical: Structured knowledge graphs significantly improve completion quality over direct generation approaches
LMMs enable OOD generalization: Pre-trained LMMs can effectively transfer knowledge across domains without domain-specific training
Scale improves performance: Larger models show better knowledge extraction capabilities and generate more accurate completions
Training-free advantage: The approach demonstrates that pre-trained LMMs can be effectively used for MMC without additional training
Limitations: The method focuses only on image and text modalities, and can still produce hallucinations that might affect generation quality
The authors suggest that future work could incorporate Retrieval-Augmented Generation to mitigate hallucinations and extend the approach to other modalities beyond text and images.
Comments
The essence of this paper is effectively leveraging LLM capabilities to extract structured knowledge, then orchestrating existing generation tools (like diffusion models) to complete missing modalities. Its key innovation lies in using knowledge graphs as a bridge between modalities: extracting structured representations of entities and relationships that guide both generation and ranking of missing content, all without requiring additional training.