Categories
Daily Publication
CompSci301
Note
Research
CompSci201
Misc
2026
Thoughts After Watching Mercy
2025
LeCun's talk on Advanced AI
2024
Converting NetEase Music Playlists to Spotify: A Python Solution
2023
Pull.py for CS301
Screenshots from music audio processing workshop
Dive into Diffusion Model
Weekly Report
2022
Course selection
VMS288: Web Based Multimedia Cummunication
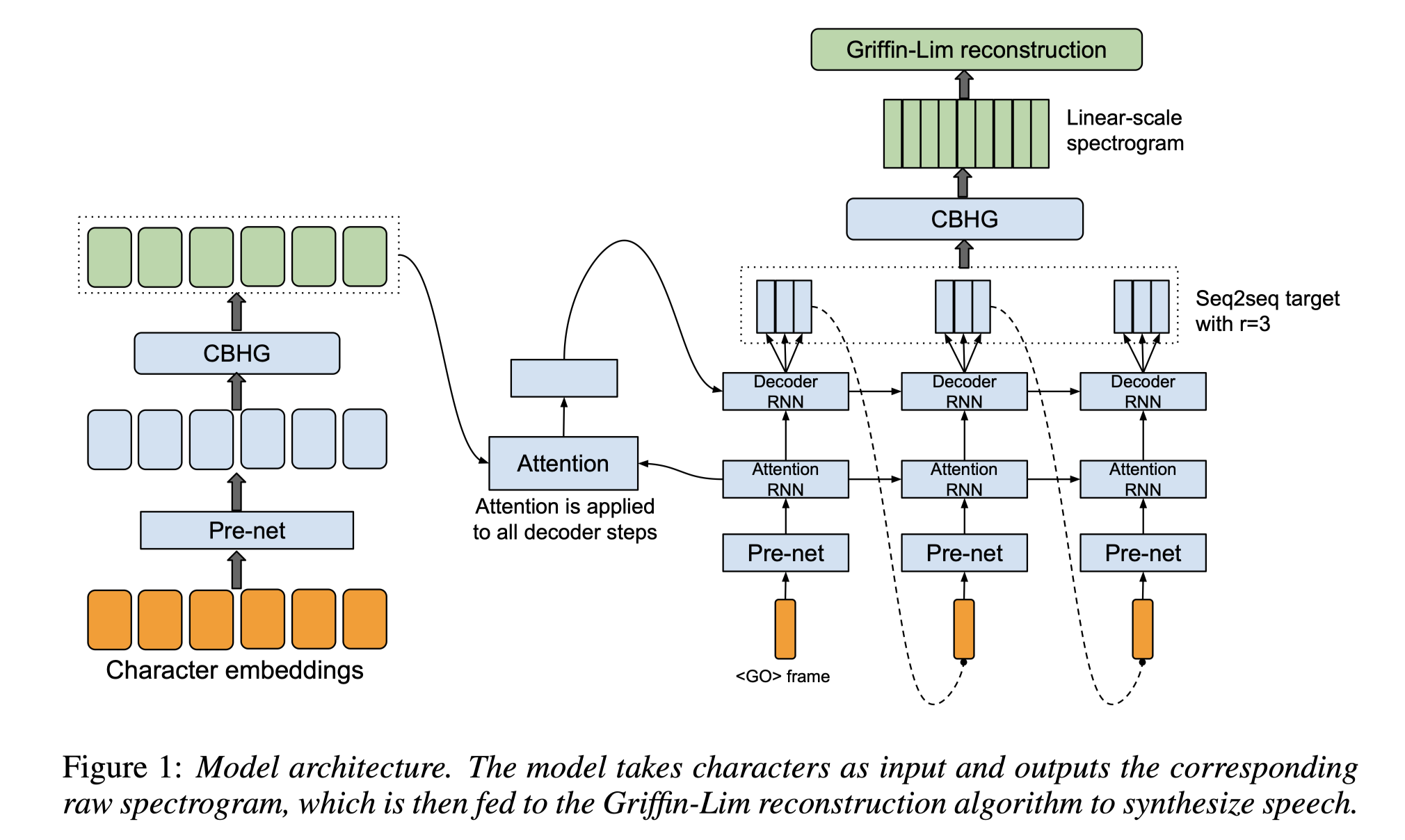
TTS Note
GRE/Toefl备考个人经历
DLS Note
Jupyter Lab Keys
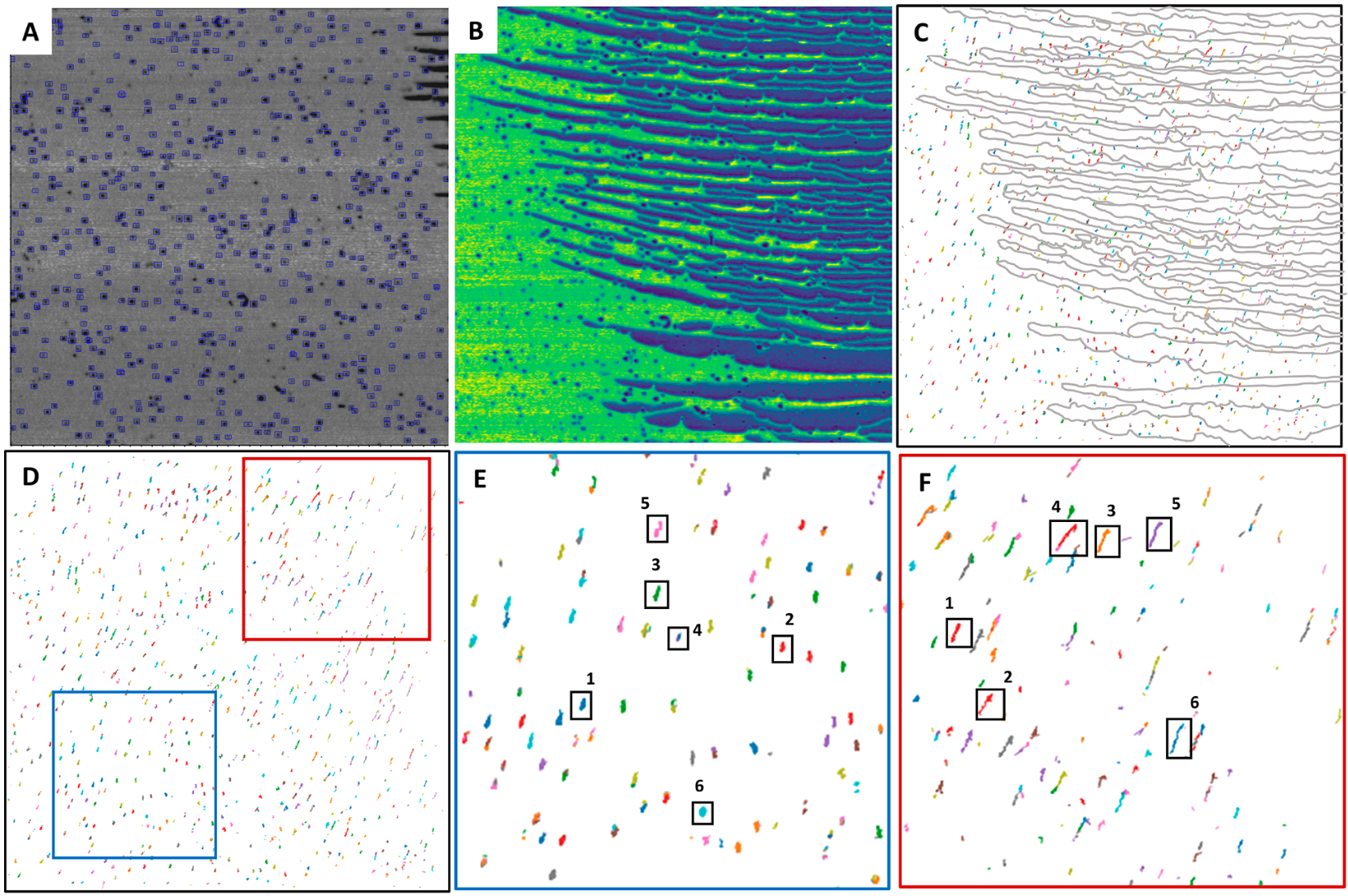
Quantifying nanoparticles through deep learning
2021
Pull.py for cs201
2025届返校指南
CS201-Monday
My First Post